22 Additional Hypothesis Tests
22.1 Objectives
Conduct and interpret a goodness of fit test using both Pearson’s chi-squared and randomization to evaluate the independence between two categorical variables.
Explain how the chi-squared distribution relates to the normal distribution, where it is used, and how changing parameters impacts the shape of the distribution.
Conduct and interpret a hypothesis test for equality of two means and equality of two variances using both permutation and the CLT.
Conduct and interpret a hypothesis test for paired data.
Know and check the assumptions for Pearson’s chi-square and two-sample \(t\) tests.
22.2 Homework
22.2.1 Problem 1
Golf balls. Repeat the analysis of the golf ball problem from earlier in the book. This time, we’ll compare the observed proportions to a distribution, sometimes called a chi-squared goodness-of-fit test.
- Load the data and tally the data into a table. The data is in
golf_balls.csv.
golf_balls <- read_csv("data/golf_balls.csv")
head(golf_balls)## # A tibble: 6 × 1
## number
## <dbl>
## 1 3
## 2 2
## 3 1
## 4 4
## 5 4
## 6 3
tally(~number, data = golf_balls)## number
## 1 2 3 4
## 137 138 107 104- Using the function
chisq.testconduct a hypothesis test of equally likely distribution of balls. You may have to read the help menu.
The hypotheses from Chapter 20 are
\(H_0\): All of the numbers are equally likely. \(\pi_1 = \pi_2 = \pi_3 = \pi_4\) or \(\pi_1 = \frac{1}{4}, \pi_2 = \frac{1}{4}, \pi_3 = \frac{1}{4} = \pi_4 = \frac{1}{4}\)
\(H_A\): There is some other distributio of the numbers in the population. At least one population proportion is not \(\frac{1}{4}\).
We use the chisq.test() function in R to conduct the hypothesis test.
chisq.test(tally(~number, data = golf_balls),
p = c(0.25, 0.25, 0.25, 0.25))##
## Chi-squared test for given probabilities
##
## data: tally(~number, data = golf_balls)
## X-squared = 8.4691, df = 3, p-value = 0.03725The p-value is 0.03725. We reject the null hypothesis; there is evidence that there is some other distribution of the numbers in the population (at least one population proportion is different from \(\frac{1}{4}\)).
- Repeat part b), but assume balls with the numbers 1 and 2 occur 30% of the time and balls with 3 and 4 occur 20%.
chisq.test(tally(~number, data = golf_balls),
p = c(0.3, 0.3, 0.2, 0.2))##
## Chi-squared test for given probabilities
##
## data: tally(~number, data = golf_balls)
## X-squared = 2.4122, df = 3, p-value = 0.4914The p-value is 0.4914. We fail to reject the null hypothesis; there is not enough evidence to say that the distribution of numbers in the population is different from 0.3, 0.3, 0.2 and 0.2.
- Repeat part c), but use a randomization test this time. You should use \(\chi^2\), the chi-squared test statistic, as your test statistic.
Let’s calculate the observed value of the test statistic.
obs <- chisq(~number, data = golf_balls)
obs## X.squared
## 8.469136Next, we will use a randomization process to find the sampling distribution of our test statistic. Because there is only a single variable, we can’t use the shuffle() function. Instead, think about what we want to do.
Under the null hypothesis, all of the numbers (1 through 4) are equally likely. We will generate a sample of the numbers 1 through 4 that is the same size as our golf_balls data set (486 observations). Then, we’ll use the chisq() function to find the chi-square test statistic based on that sample.
## X.squared
## 4.584362This assumes that the probability of each number is the same ($ for each number). You can also change the probability of each number within your sample().
Now, let’s do the same thing many times.
We plot the sampling distribution and compare our observed test statistic (shown as a red line). The chi-square distribution with 3 degrees of freedom (4 categories/golf ball numbers minus 1) is shown as a dark blue curve.
results %>%
gf_dhistogram(~X.squared, fill = "cyan", color = "black") %>%
gf_vline(xintercept = obs, color = "red") %>%
gf_theme(theme_classic()) %>%
gf_dist("chisq", df = 3, color = "darkblue") %>%
gf_labs(title = "Sampling distribution of chi-squared test statistic",
subtitle = "For the distribution of golf ball numbers",
x = "Test statistic")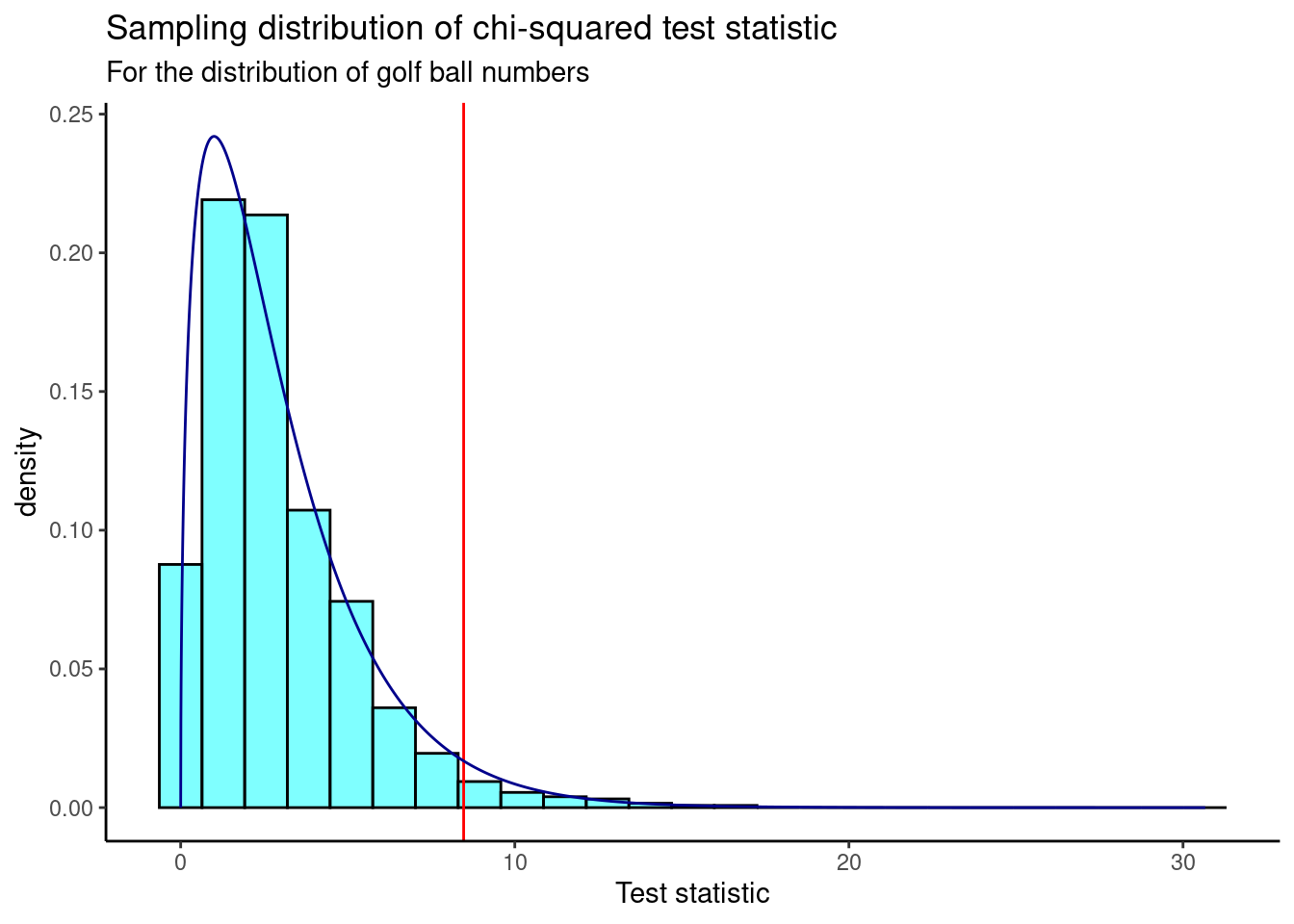
We find the p-value using prop1().
prop1(~X.squared >= obs, data = results)## prop_TRUE
## 0.03196803Based on this p-value, we reject the null hypothesis; there is evidence that at least one population proportion is different from \(\frac{1}{4}\).
22.2.2 Problem 2
Test of variance. We have not performed a test of variance so we will create our own. Use the mlb_obp_subset data set, with only the IF and OF positions, to conduct a test of equality of two variances. The hypotheses are:
\(H_0:\ \sigma^2_{IF} = \sigma^2_{OF}\). There is no difference in the variance of on-base percentage for infielders and outfielders.
\(H_A:\ \sigma^2_{IF} \neq \sigma^2_{OF}\). There is a difference in variances.
Use the difference in sample standard deviations as your test statistic. Using a randomization test, find the \(p\)-value and discuss your decision. Make sure to include all steps of a hypothesis test.
- Using the MLB from the lesson, subset on
IFandOF.
mlb_obp <- read_csv("data/mlb_obp.csv")
mlb_prob3 <- mlb_obp %>%
filter(position=="IF"|position=="OF") %>%
droplevels()
summary(mlb_prob3)## position obp
## Length:274 Min. :0.1740
## Class :character 1st Qu.:0.3100
## Mode :character Median :0.3310
## Mean :0.3327
## 3rd Qu.:0.3530
## Max. :0.4370The function droplevels() gets rid of C and DH in the factor levels.
- Create a side-by-side boxplot.
mlb_prob3 %>%
gf_boxplot(obp~position) %>%
gf_theme(theme_classic())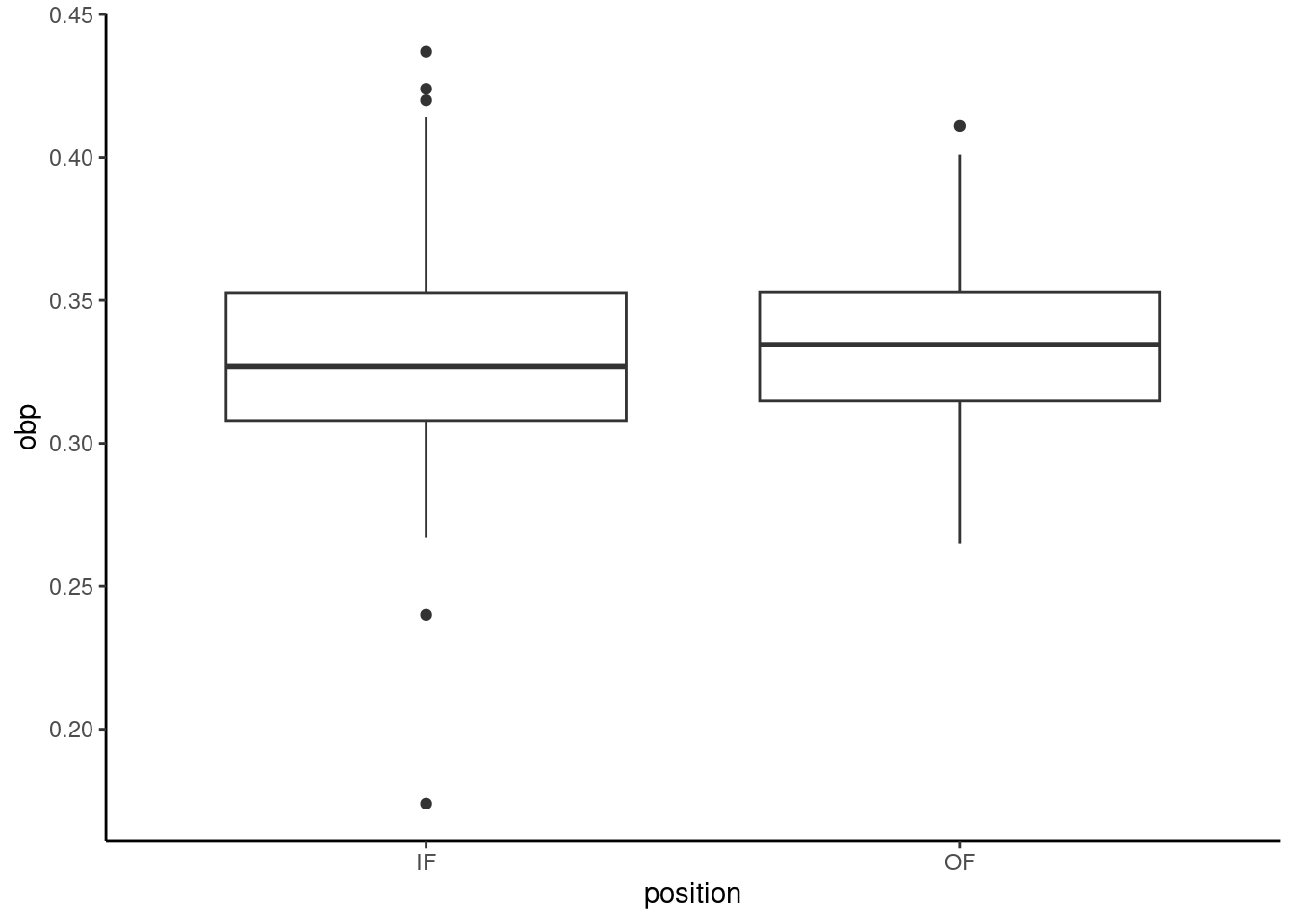
The hypotheses are:
\(H_0\): \(\sigma^2_{IF}=\sigma^2{OF}\). There is no difference in the variance of on base percentage for infielders and outfielders.
\(H_A\): \(\sigma^2_{IF}\neq \sigma^2_{OF}\). There is a difference in variances.
- Use the differences in sample standard deviations as your test statistic. Using a permutation test, find the \(p\)-value and discuss your decision.
## # A tibble: 2 × 2
## position stat
## <chr> <dbl>
## 1 IF 0.0371
## 2 OF 0.0294## [1] 0.007651101Let’s write a function to shuffle the position.
perm_stat <- function(x){
x %>%
mutate(position=shuffle(position)) %>%
summarize(stat=sd(obp[position=="IF"])-sd(obp[position=="OF"])) %>%
pull()
}
set.seed(443)
results<-do(1000)*perm_stat(mlb_prob3)
results %>%
gf_histogram(~perm_stat,fill="cyan",color="black") %>%
gf_vline(xintercept=obs,color="red") %>%
gf_theme(theme_classic()) %>%
gf_labs(title="Sampling distribution of difference in variances",
subtitle="Randomization permutation test",
x="Test statistic")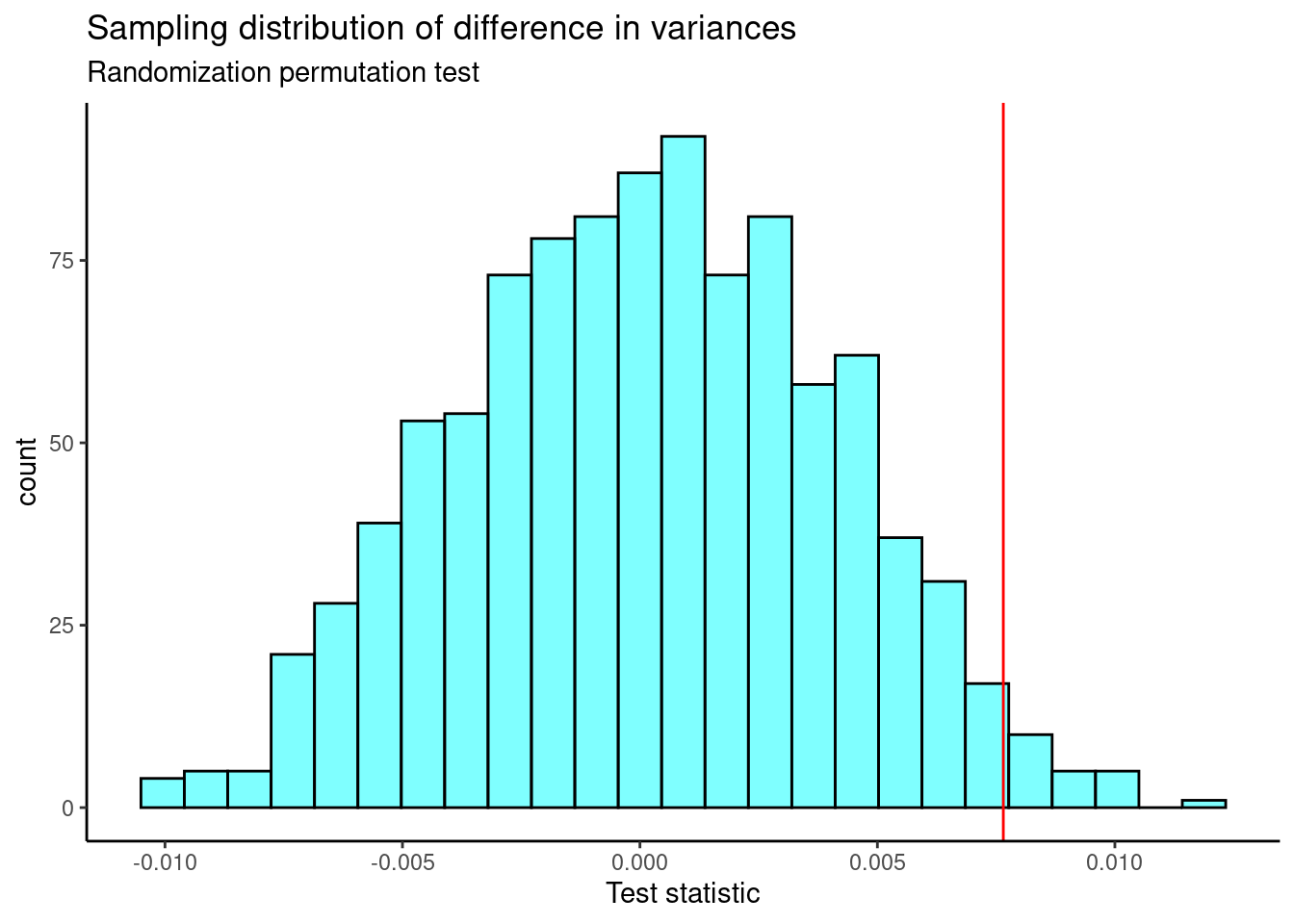
The \(p\)-value is
2*prop1(~(perm_stat>=obs),data=results)## prop_TRUE
## 0.04395604This is a two sided test since we did not know in advance which variance would be larger. We reject the hypothesis of equal variance but the \(p\)-value is too close to the significance level. The conclusion is suspect. We need more data.
22.2.3 Problem 3
Exploration of the chi-squared and \(t\) distributions.
- In
R, plot the pdf of a random variable with the chi-squared distribution with 1 degree of freedom. On the same plot, include the pdfs with degrees of freedom of 5, 10 and 50. Describe how the behavior of the pdf changes with increasing degrees of freedom.
gf_dist("chisq",df=1,col=1) %>%
gf_dist("chisq",df=5,col=2) %>%
gf_dist("chisq",df=10,col=3) %>%
gf_dist("chisq",df=50,col=4) %>%
gf_lims(y=c(0, 0.25)) %>%
gf_labs(y="f(x)") %>%
gf_theme(theme_classic()) 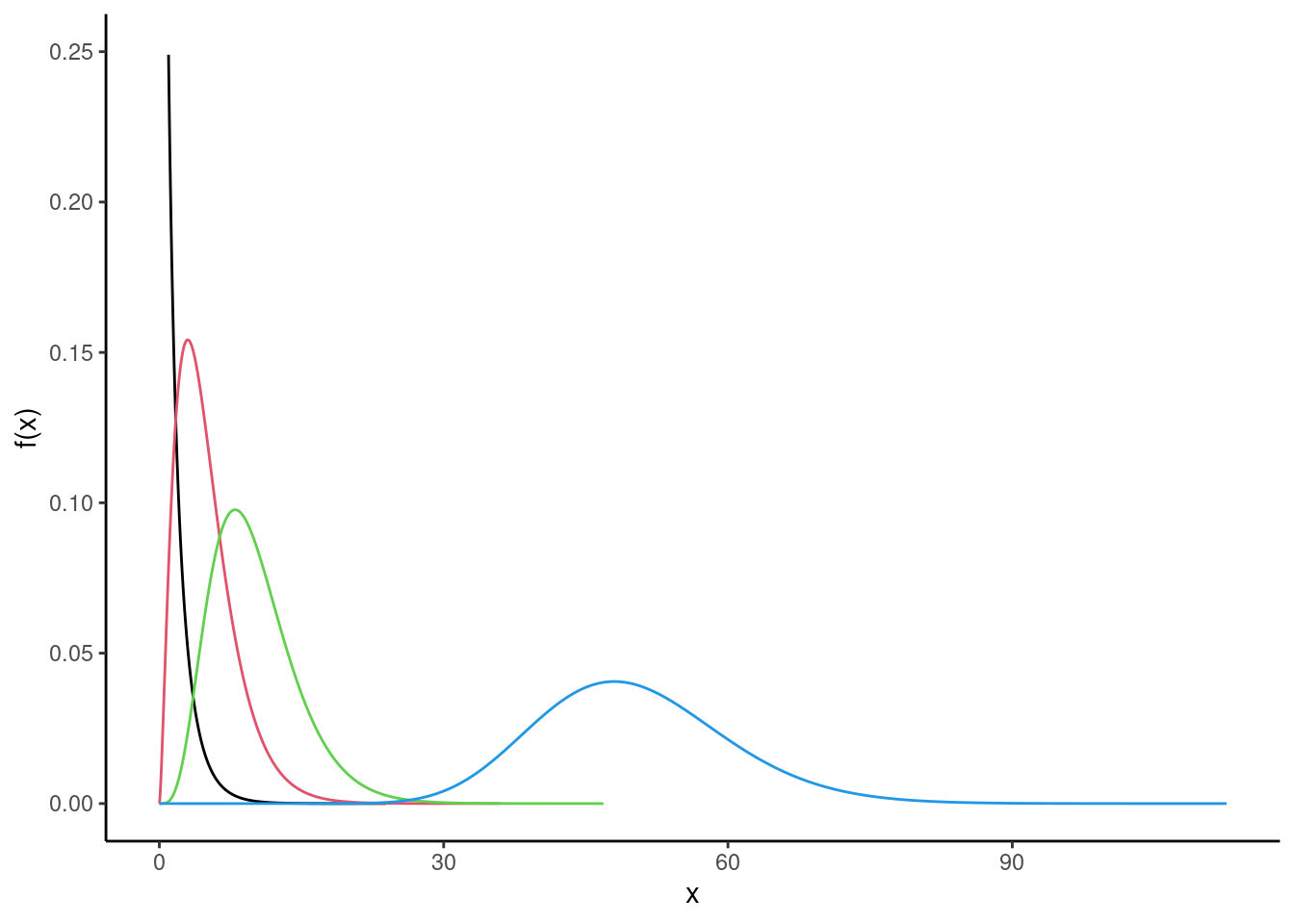
The “bump” moves to the rights as the degrees of freedom increase.
The plot should have a legend, but I could not find a way to do it within ggformula so here it is in ggplot.
ggplot(data = data.frame(x = c(0, 75)), aes(x)) +
stat_function(fun = dchisq, n = 101,
args = list(df = 1),
mapping=aes(col="myline1")) +
stat_function(fun = dchisq, n = 101,
args = list(df = 5),
mapping=aes(col="myline2")) +
stat_function(fun = dchisq, n = 101,
args = list(df = 10),
mapping=aes(col="myline3")) +
stat_function(fun = dchisq, n = 101,
args = list(df = 50),
mapping=aes(col="myline4")) +
ylab("") +
scale_y_continuous(breaks = NULL) +
theme_classic()+
scale_colour_manual(name="Legend",
values=c(myline1="black",
myline2="red",
myline3="green",
myline4="blue"),
labels=c("df=1","df=5","df=10","df=50"))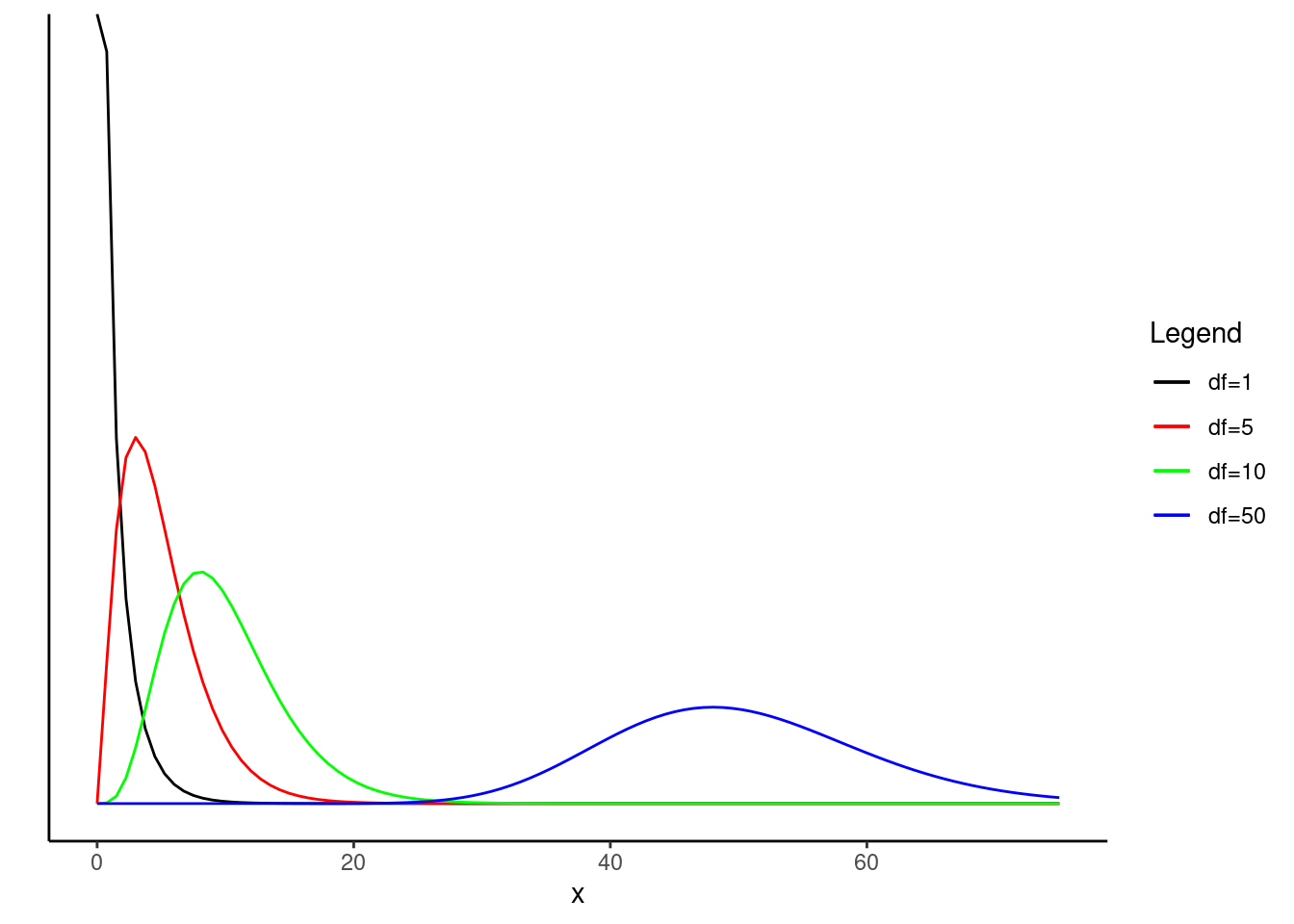
- Repeat part (a) with the \(t\) distribution. Add the pdf of a standard normal random variable as well. What do you notice?
gf_dist("t",df=1,col="black") %>%
gf_dist("t",df=5,col="red") %>%
gf_dist("t",df=10,col="green") %>%
gf_dist("t",df=50,col="blue") %>%
gf_dist("norm",lty=2,lwd=1.5) %>%
gf_lims(x=c(-4,4)) %>%
gf_labs(y="f(x)") %>%
gf_theme(theme_classic()) 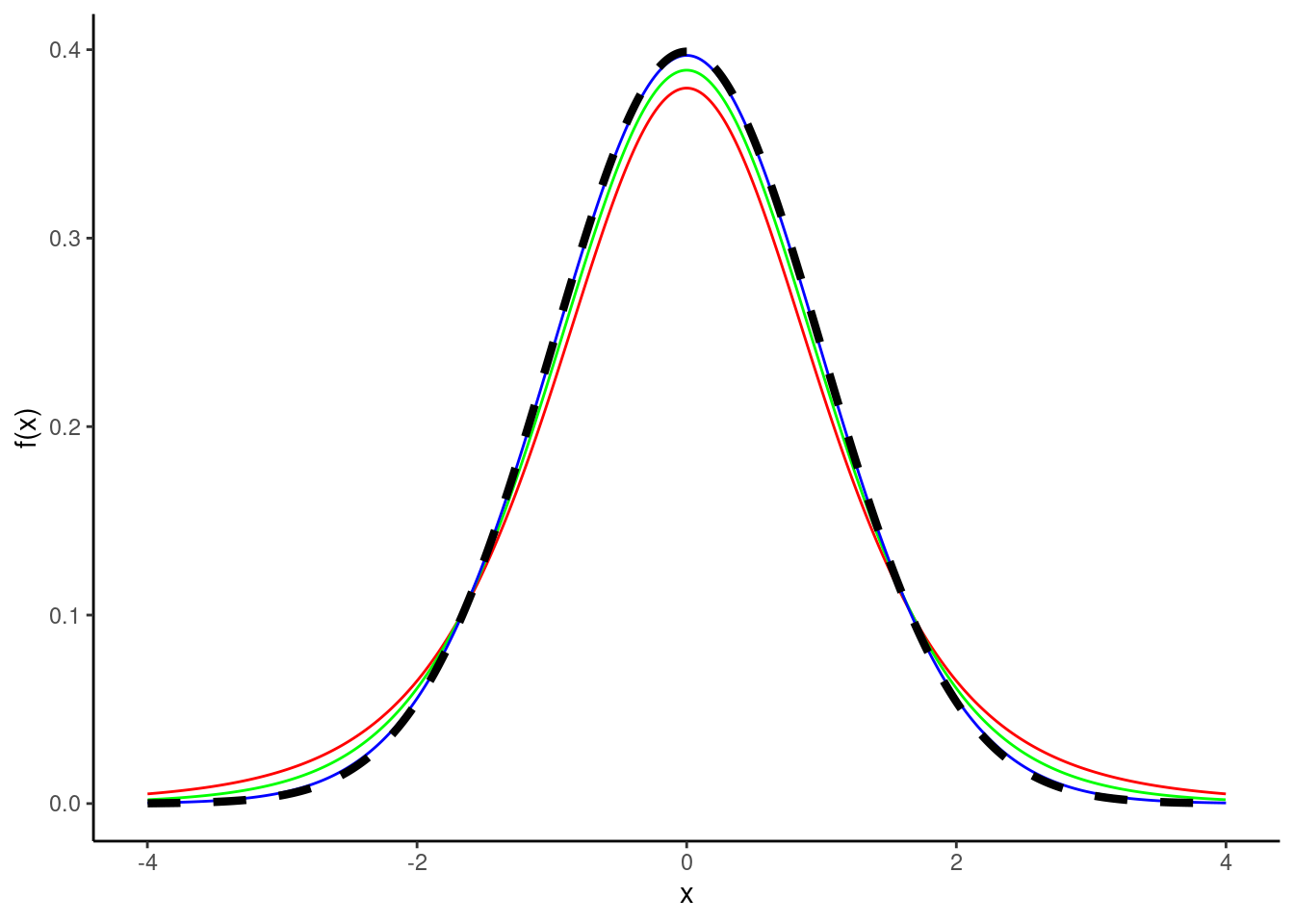
As degrees of freedom increases, the \(t\)-distribution approaches the standard normal distribution.
ggplot(data = data.frame(x = c(-4, 4)), aes(x)) +
stat_function(fun = dt, n = 101,
args = list(df = 1),
mapping=aes(col="myline1")) +
stat_function(fun = dt, n = 101,
args = list(df = 5),
mapping=aes(col="myline2")) +
stat_function(fun = dt, n = 101,
args = list(df = 10),
mapping=aes(col="myline3")) +
stat_function(fun = dt, n = 101,
args = list(df = 50),
mapping=aes(col="myline4")) +
stat_function(fun = dnorm, n = 101,
args = list(mean=0,sd=1),
linetype="dashed",
mapping=aes(col="myline5")) +
ylab("") +
scale_y_continuous(breaks = NULL) +
theme_classic()+
scale_colour_manual(name="Legend",
values=c(myline1="black",
myline2="red",
myline3="green",
myline4="blue",
myline5="grey"),
labels=c("df=1","df=5","df=10","df=50","Normal"))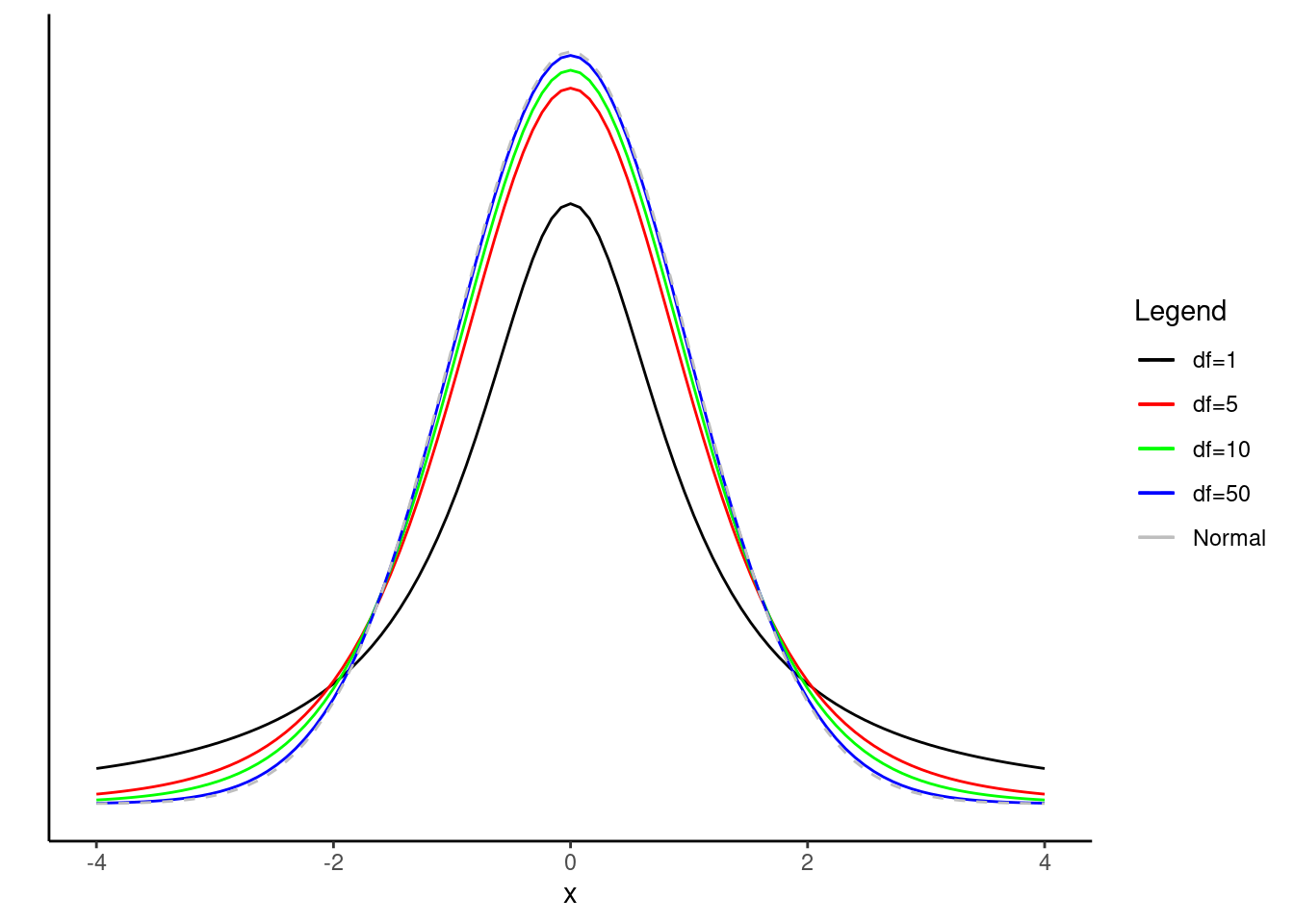
22.2.4 Problem 4
Paired data. Are textbooks actually cheaper online? Here we compare the price of textbooks at the University of California, Los Angeles’ (UCLA’s) bookstore and prices at Amazon.com. Seventy-three UCLA courses were randomly sampled in Spring 2010, representing less than 10% of all UCLA courses. When a class had multiple books, only the most expensive text was considered.
The data is in the file textbooks.csv under the data folder.
textbooks<-read_csv("data/textbooks.csv")
head(textbooks)## # A tibble: 6 × 7
## dept_abbr course isbn ucla_new amaz_new more diff
## <chr> <chr> <chr> <dbl> <dbl> <chr> <dbl>
## 1 Am Ind C170 978-0803272620 27.7 28.0 Y -0.28
## 2 Anthro 9 978-0030119194 40.6 31.1 Y 9.45
## 3 Anthro 135T 978-0300080643 31.7 32 Y -0.32
## 4 Anthro 191HB 978-0226206813 16 11.5 Y 4.48
## 5 Art His M102K 978-0892365999 19.0 14.2 Y 4.74
## 6 Art His 118E 978-0394723693 15.0 10.2 Y 4.78Each textbook has two corresponding prices in the data set: one for the UCLA bookstore and one for Amazon. Therefore, each textbook price from the UCLA bookstore has a natural correspondence with a textbook price from Amazon. When two sets of observations have this special correspondence, they are said to be paired.
To analyze paired data, it is often useful to look at the difference in outcomes of each pair of observations. In textbooks, we look at the difference in prices, which is represented as the diff variable. It is important that we always subtract using a consistent order; here Amazon prices are always subtracted from UCLA prices.
- Is this data tidy? Explain.
Yes, because each row is a textbook and each column is a variable.
- Make a scatterplot of the UCLA price versus the Amazon price. Add a 45 degree line to the plot.
textbooks %>%
gf_point(ucla_new~amaz_new) %>%
gf_abline(slope=1,intercept = 0,color="darkblue") %>%
gf_theme(theme_classic()) %>%
gf_labs(x="Amazon",y="UCLA")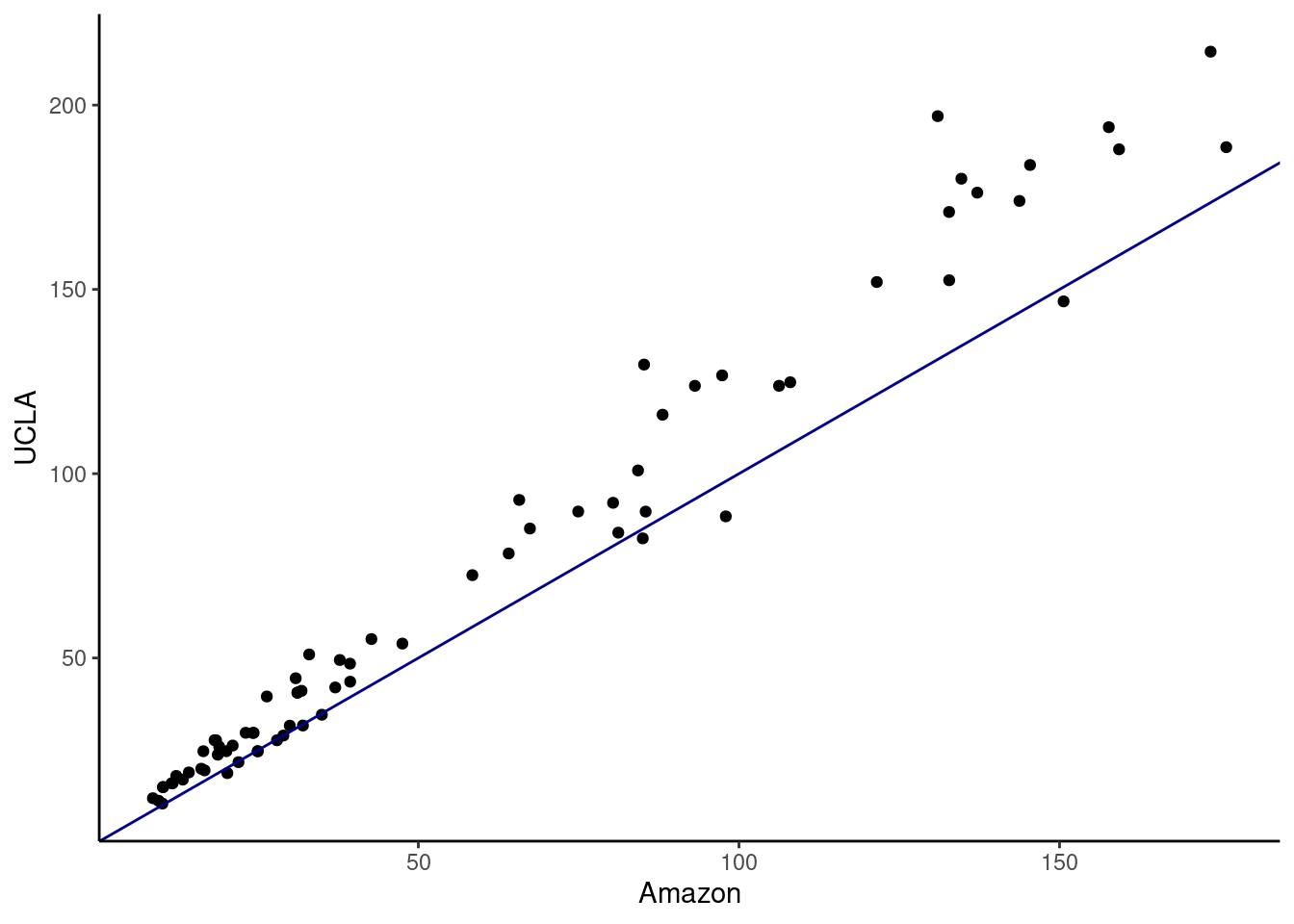
It appears the books at the UCLA bookstore are more expensive. One way to test this is with a regression model; we will learn about in the next block.
- Make a histogram of the differences in price.
textbooks %>%
gf_histogram(~diff,fill="cyan",color="black") %>%
gf_theme(theme_classic()) %>%
gf_labs(title="Distribution of price differences",
x="Price difference between UCLA and Amazon")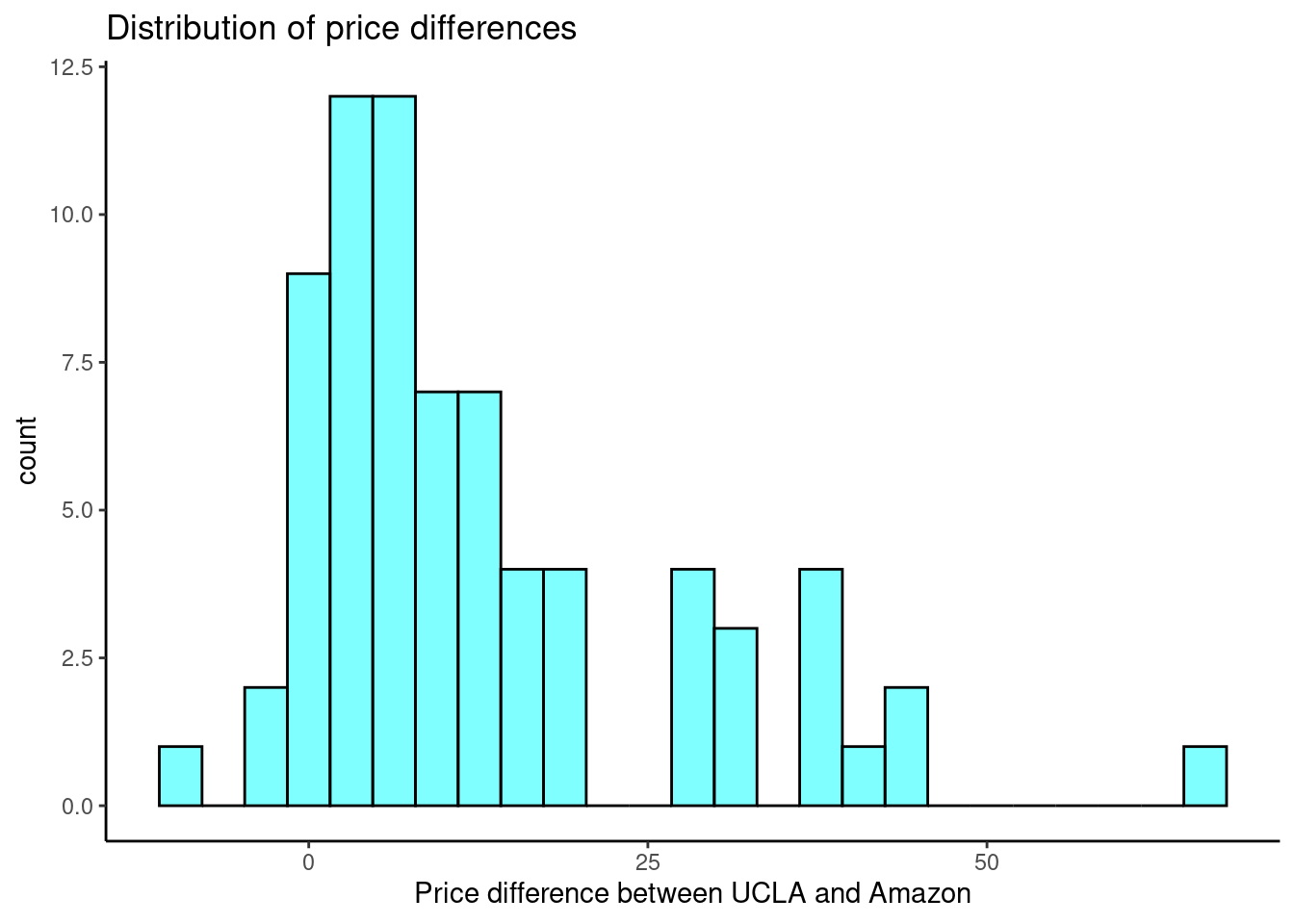
The distribution is skewed.
The hypotheses are:
\(H_0\): \(\mu_{diff}=0\). There is no difference in the average textbook price.
\(H_A\): \(\mu_{diff} \neq 0\). There is a difference in average prices.
- To use a \(t\) distribution, the variable
diffhas to be independent and normally distributed. Since the 73 books represent less than 10% of the population, the assumption that the random sample is independent is reasonable. Check normality usingqqnorsim()from theopenintropackage. It generates 8 qq plots of simulated normal data that you can use to judge thediffvariable.
qqnormsim(diff,textbooks)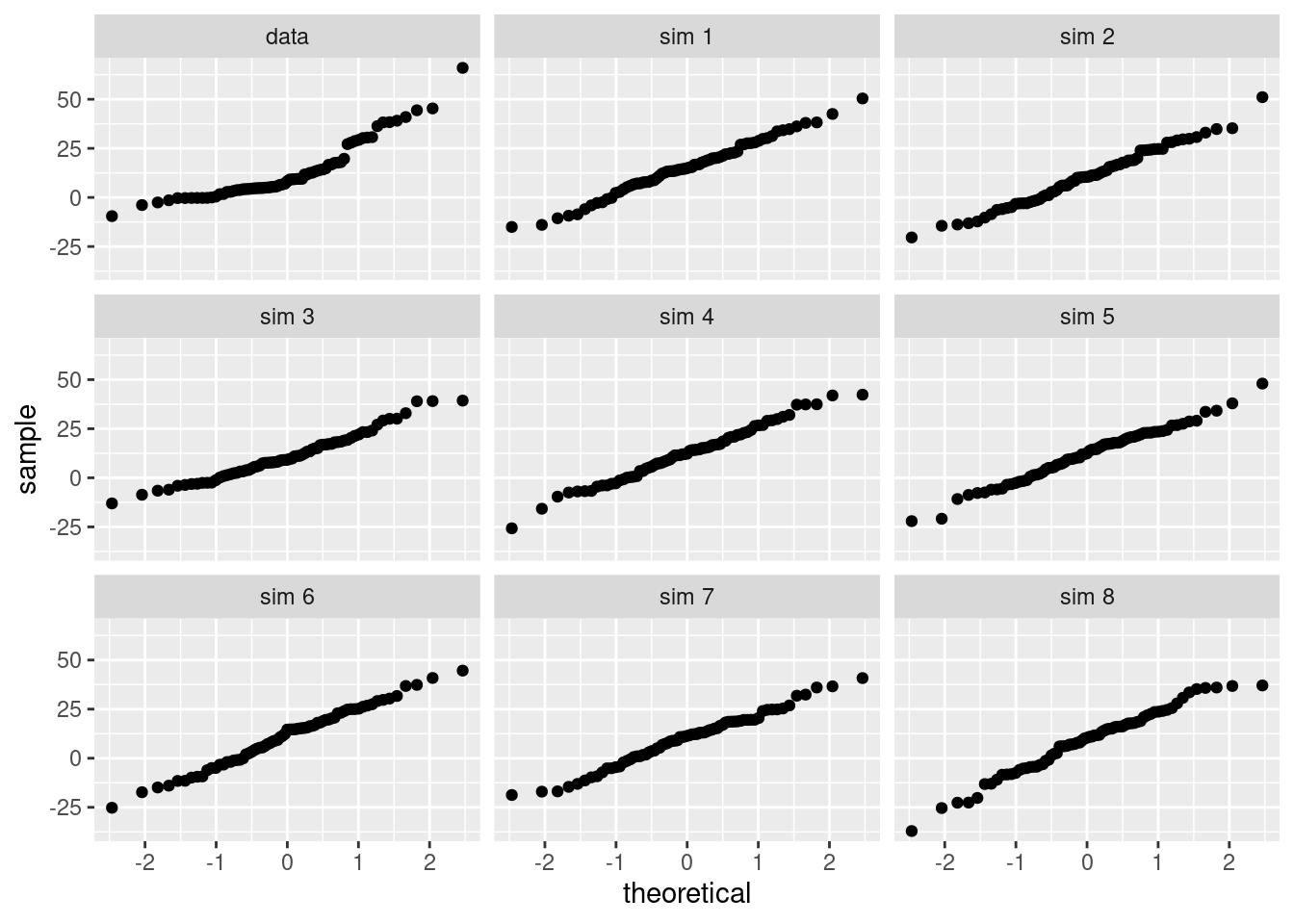
The normality assumption is suspect but we have a large sample so it should be acceptable to use the \(t\).
- Run a \(t\) test on the
diffvariable. Report the \(p\)-value and conclusion.
t_test(~diff,textbooks)##
## One Sample t-test
##
## data: diff
## t = 7.6488, df = 72, p-value = 6.928e-11
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 9.435636 16.087652
## sample estimates:
## mean of x
## 12.76164We did not have to use the paired option since we already took the difference. Here is an example of using the paired option.
t_test(textbooks$ucla_new,textbooks$amaz_new,paired=TRUE)##
## Paired t-test
##
## data: textbooks$ucla_new and textbooks$amaz_new
## t = 7.6488, df = 72, p-value = 6.928e-11
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## 9.435636 16.087652
## sample estimates:
## mean difference
## 12.76164The \(p\)-value is so small that we don’t believe the average price of the books from the UCLA bookstore and Amazon are the same.
- If there is really no differences between book sources, the variable
moreis a binomial and under the null the probably of success is \(\pi = 0.5\). Run a hypothesis test using the variablemore.
inspect(textbooks)##
## categorical variables:
## name class levels n missing
## 1 dept_abbr character 41 73 0
## 2 course character 66 73 0
## 3 isbn character 73 73 0
## 4 more character 2 73 0
## distribution
## 1 Mgmt (8.2%), Pol Sci (6.8%) ...
## 2 10 (4.1%), 101 (2.7%), 180 (2.7%) ...
## 3 978-0030119194 (1.4%) ...
## 4 Y (61.6%), N (38.4%)
##
## quantitative variables:
## name class min Q1 median Q3 max mean sd n missing
## 1 ucla_new numeric 10.50 24.70 43.56 116.00 214.5 72.22192 59.65913 73 0
## 2 amaz_new numeric 8.60 20.21 34.95 88.09 176.0 59.46027 48.99557 73 0
## 3 diff numeric -9.53 3.80 8.23 17.59 66.0 12.76164 14.25530 73 0We have 45 books that were more expensive out of the total of 73.
prop_test(45,73,p=0.5)##
## 1-sample proportions test with continuity correction
##
## data: 45 out of 73
## X-squared = 3.5068, df = 1, p-value = 0.06112
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.4948968 0.7256421
## sample estimates:
## p
## 0.6164384Notice that this test failed to reject the null hypothesis. In the paired test, the evidence was so strong but in the binomial model it is not. There is a loss of information making a discrete variable out of a continuous one.
- Could you use a permutation test on this example? Explain.
Yes, but you have to be careful because you want to keep the pairing so you can’t just shuffle the names. You have to shuffle the names within the paired values. This means to simply randomly switch the names within a row. This is easier to do by just multiplying the diff column by a random choice of -1 and 1.
## [1] -1 -1 1 1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 1 1 1 1 -1 1 -1 -1
## [26] -1 -1 -1 -1 -1 -1 1 -1 -1 1 -1 -1 1 1 1 -1 1 -1 1 1 1 1 1 -1 -1
## [51] 1 -1 -1 -1 -1 -1 1 1 -1 1 -1 -1 -1 -1 -1 1 1 -1 1 -1 -1 -1 1
set.seed(406)
results <- do(1000)*mean((~diff*sample(c(-1,1),size=73,replace = TRUE)),data=textbooks)
results %>%
gf_histogram(~mean,fill="cyan",color="black") %>%
gf_theme(theme_classic()) %>%
gf_labs(title="Randomization sampling distribution of mean of differences in price",
x="Mean of price difference")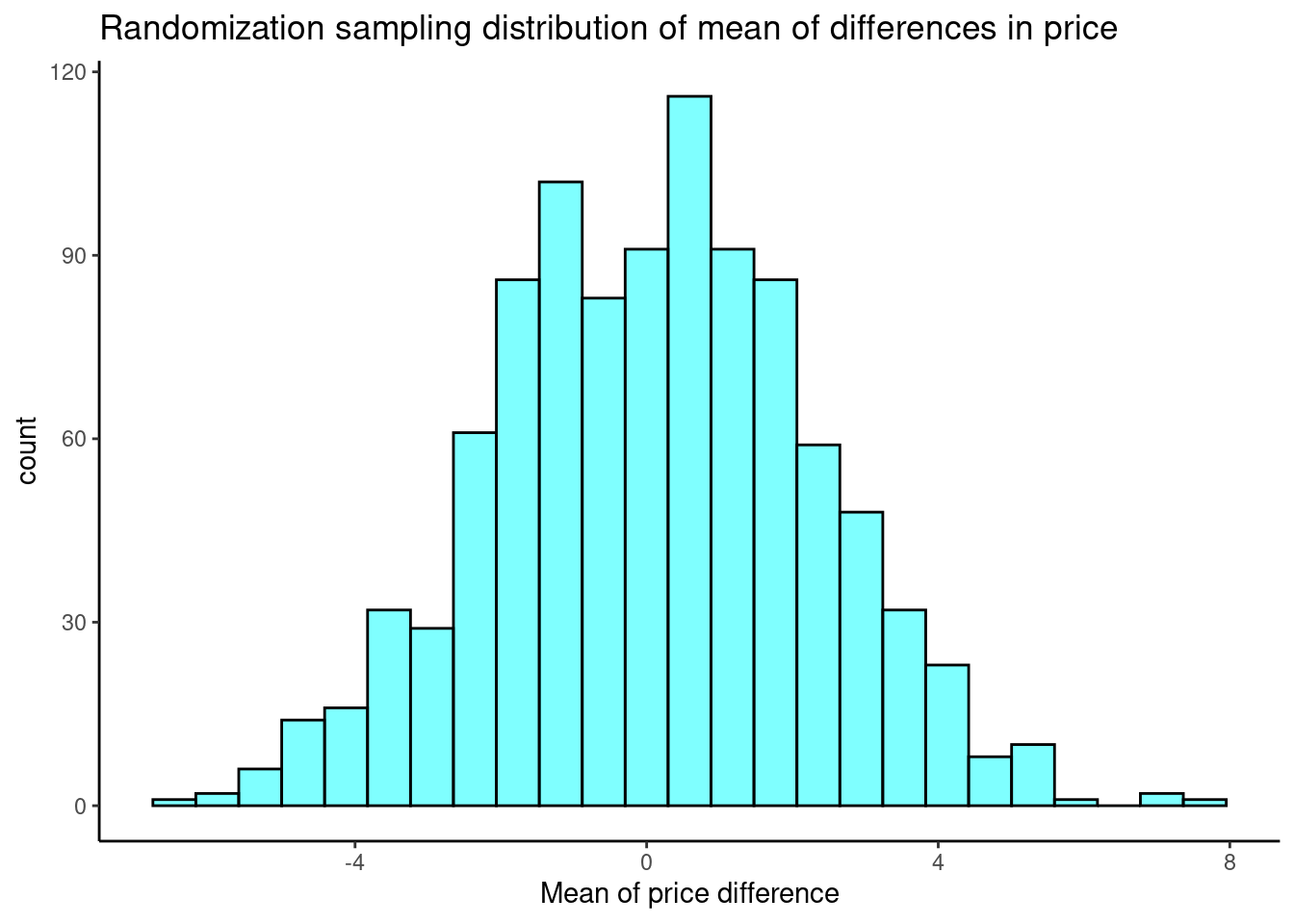
We need our observed test statistic to calculate a \(p\)-value.
## [1] 12.76164
prop1((~mean>=obs_stat),data=results)## prop_TRUE
## 0.000999001None of the permuted values is at or greater that the observed value.