19 Hypothesis Testing with Simulation
19.1 Objectives
Know and properly use the terminology of a hypothesis test, to include: null hypothesis, alternative hypothesis, test statistic, \(p\)-value, randomization test, one-sided test, two-sided test, statistically significant, significance level, type I error, type II error, false positive, false negative, null distribution, and sampling distribution.
Conduct all four steps of a hypothesis test using randomization.
Discuss and explain the ideas of decision errors, one-sided versus two-sided tests, and the choice of a significance level.
19.2 Decision making under uncertainty
At this point, it is useful to take a look at where we have been in this book and where we are going. We did this in the case study, but we want to discuss it again in a little more detail. We first looked at descriptive models to help us understand our data. This also required us to get familiar with software. We learned about graphical summaries, data collection methods, and summary metrics.
Next we learned about probability models. These models allowed us to use assumptions and a small number of parameters to make statements about data (a sample) and also to simulate data. We found that there is a close tie between probability models and statistical models. In our first efforts at statistical modeling, we started to use data to create estimates for parameters of a probability model.
Now we are moving more in depth into statistical models. This is going to tie all the ideas together. We are going to use data from a sample and ideas of randomization to make conclusions about a population. This will require probability models, descriptive models, and some new ideas and terminology. We will generate point estimates for a metric designed to answer the research question and then find ways to determine the variability of the metric. In Figure 19.1, we demonstrate this relationship between probability and statistical models.
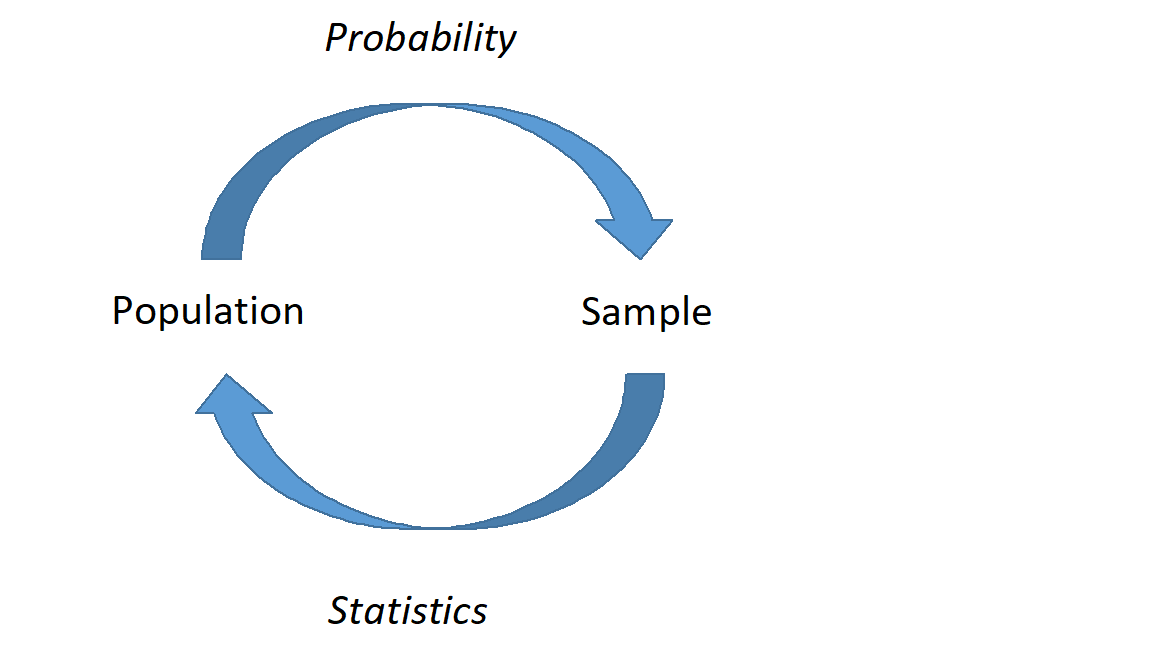
Figure 19.1: A graphical representation of probability and statistics. In probability, we describe what we expect to happen in a sample if we know the underlying process; in statistics, we don’t know the underlying process, and must infer about the population based on representative samples.
Computational/Mathematical and hypothesis testing/confidence intervals context
We are going to be using data from a sample of the population to make decisions about the population. There are many approaches and techniques for this. In this book, we will be introducing and exploring different approaches; we are establishing foundations. As you can imagine, these ideas are varied, subtle, and at times difficult. We will just be exposing you to the foundational ideas. We want to make sure you understand that to become an accomplished practitioner, you must master the fundamentals and continue to learn the advanced ideas.
Historically, there have been two approaches to statistical decision making, hypothesis testing and confidence intervals. At their mathematical foundation, they are equivalent, but, sometimes in practice, they offer different perspectives on the problem. We will learn about both of these approaches.
The engines that drive the numeric results of a decision making model are either mathematical or computational. In reality, computational methods have mathematics behind them, and mathematical methods often require computer computations. The real distinction between them is the assumptions we are making about our population. Mathematical solutions typically have stricter assumptions, thus leading to a tractable mathematical solution to the sampling distribution of the test statistic, while computational models relax assumptions but may require extensive computational power. Like all problems, there is a trade off to consider when trying to choose which approach is better. There is no one universal best method. Some methods perform better in certain contexts. It is important to understand that computational methods such as the bootstrap are NOT all you need to know.
19.3 Introduction
In this chapter we will introduce hypothesis testing. It is really an extension of our last chapter, the case study. We will put more emphasis on terms and core concepts. In this chapter, we will use a computational solution but this will lead us into thinking of mathematical solutions.83 The role of the analyst is always key regardless of the perceived power of the computer. The analyst must take the research question and translate it into a numeric metric for evaluation. The analyst must decide on the type of data and its collection to evaluate the question. The analyst must evaluate the variability in the metric and determine what that means in relation to the original research question. The analyst must propose an answer.
19.4 Hypothesis testing
We will continue to emphasize the ideas of hypothesis testing through a data-driven example, but also via analogy to the US court system. So let’s begin our journey.
Example:
You are annoyed by TV commercials. You suspect that there were more commercials in the basic TV channels, typically the local area channels, than in the premium channels you pay extra for. To test this claim, hypothesis, you want to collect some data and draw a conclusion. How would you collect this data?
Here is one approach: we watch 20 random half hour shows of live TV. Ten of those hours are basic TV and the other ten are premium. In each case, you record the total length of commercials during each show.
Exercise: Is this enough data? You decide to have your friends help you, so you actually only watched 5 hours and got the rest of the data from your friends. Is this a problem?
We cannot determine if this is enough data without some type of subject matter knowledge. First, we need to decide what metric to use to determine if a difference exists (more to come on this). Second, we need to decide how big of a difference, from a practical standpoint, is of interest. Is a loss of 1 minute of TV show enough to say there is a difference? How about 5 minutes? These are not statistical questions, but depend on the context of the problem and often require subject matter expertise to answer. Often, data is collected without thought to these considerations. There are several methods that attempt to answer these questions. They are loosely called sample size calculations. This book will not focus on sample size calculations and will leave it to the reader to learn more from other sources. For the second exercise question, the answer depends on the protocol and operating procedures used. If your friends are trained on how to measure the length of commercials, what counts as an ad, and their skills are verified, then it is probably not a problem to use them to collect data. Consistency in measurement is the key.
The file ads.csv contains the data. Let’s read the data into R and start to summarize. Remember to load the appropriate R packages.
ads <- read_csv("data/ads.csv")
ads## # A tibble: 10 × 2
## basic premium
## <dbl> <dbl>
## 1 6.95 3.38
## 2 10.0 7.8
## 3 10.6 9.42
## 4 10.2 4.66
## 5 8.58 5.36
## 6 7.62 7.63
## 7 8.23 4.95
## 8 10.4 8.01
## 9 11.0 7.8
## 10 8.52 9.58
glimpse(ads)## Rows: 10
## Columns: 2
## $ basic <dbl> 6.950, 10.013, 10.620, 10.150, 8.583, 7.620, 8.233, 10.350, 11…
## $ premium <dbl> 3.383, 7.800, 9.416, 4.660, 5.360, 7.630, 4.950, 8.013, 7.800,…Notice that this data may not be tidy; what does each row represent and is it a single observation? We don’t know how the data was obtained, but if each row represents a different friend who watches one basic and one premium channel, then it is possible this data is tidy. We want each observation to be a single TV show, so let’s clean up, or tidy, our data. Remember to ask yourself “What do I want R to do?” and “What does it need to do this?” We want one column that specifies the channel type and another to specify the total length of the commercials.
We need R to put, or pivot, the data into a longer form. We need the function pivot_longer(). For more information type vignette("pivot") at the command prompt in R.
ads <- ads %>%
pivot_longer(cols = everything(), names_to = "channel", values_to = "length")
ads## # A tibble: 20 × 2
## channel length
## <chr> <dbl>
## 1 basic 6.95
## 2 premium 3.38
## 3 basic 10.0
## 4 premium 7.8
## 5 basic 10.6
## 6 premium 9.42
## 7 basic 10.2
## 8 premium 4.66
## 9 basic 8.58
## 10 premium 5.36
## 11 basic 7.62
## 12 premium 7.63
## 13 basic 8.23
## 14 premium 4.95
## 15 basic 10.4
## 16 premium 8.01
## 17 basic 11.0
## 18 premium 7.8
## 19 basic 8.52
## 20 premium 9.58Looks good. Let’s summarize the data.
inspect(ads)##
## categorical variables:
## name class levels n missing
## 1 channel character 2 20 0
## distribution
## 1 basic (50%), premium (50%)
##
## quantitative variables:
## name class min Q1 median Q3 max mean sd n missing
## 1 length numeric 3.383 7.4525 8.123 9.68825 11.016 8.03215 2.121412 20 0This summary is not what we want, since we want to break it down by channel type.
favstats(length ~ channel, data = ads)## channel min Q1 median Q3 max mean sd n missing
## 1 basic 6.950 8.30375 9.298 10.30000 11.016 9.2051 1.396126 10 0
## 2 premium 3.383 5.05250 7.715 7.95975 9.580 6.8592 2.119976 10 0Exercise: Visualize the data using a boxplot.
ads %>%
gf_boxplot(channel ~ length) %>%
gf_labs(title = "Commercial Length",
subtitle = "Random 30 minute shows for 2 channel types",
x = "Length", y = "Channel Type" ) %>%
gf_theme(theme_bw)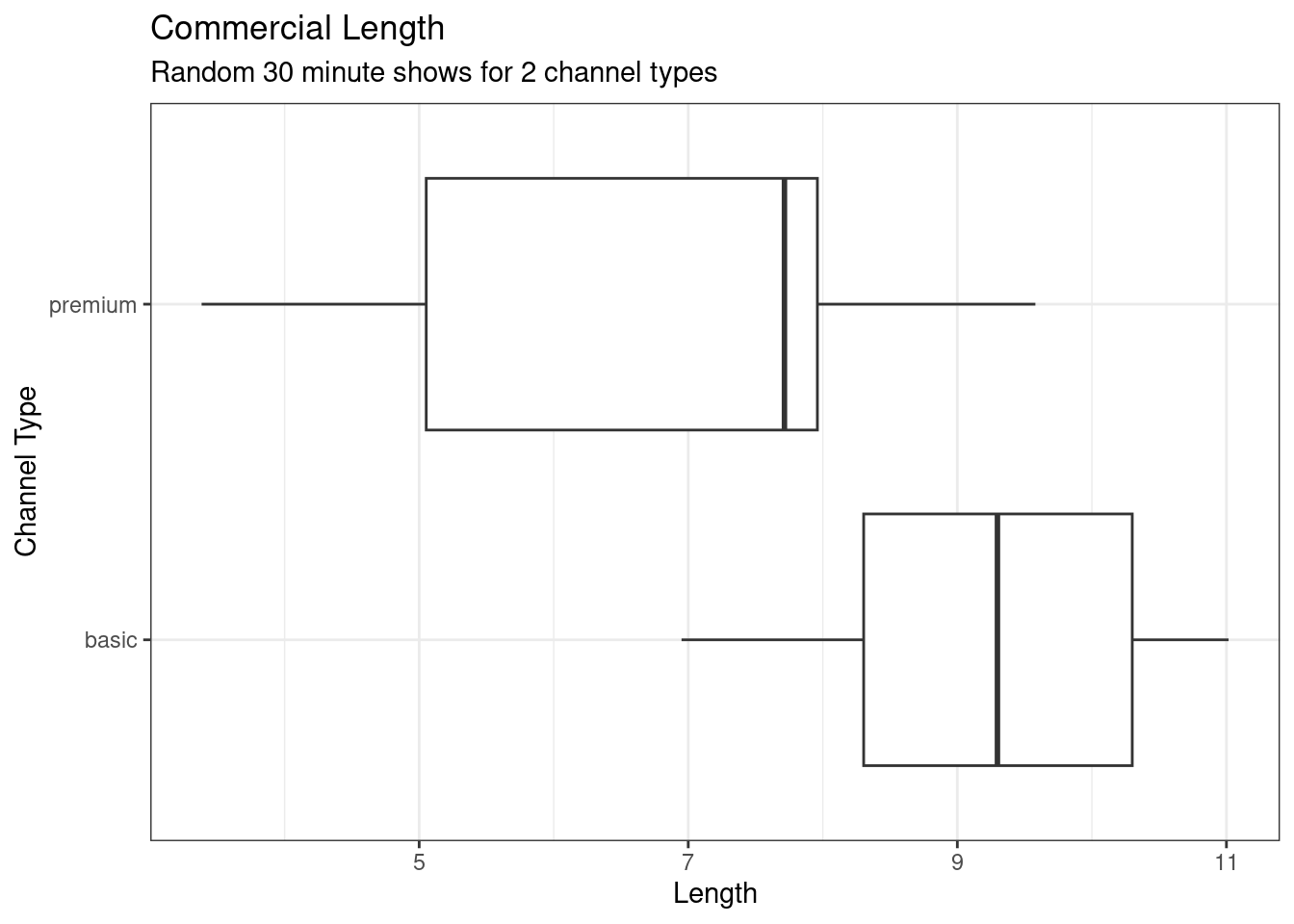
It appears that the premium channels are skewed to the left. A density plot may help us compare the distributions and see the skewness, Figure 19.2.
ads %>%
gf_dens(~length, color = ~channel)%>%
gf_labs(title = "Commercial Length",
subtitle = "Random 30 minute shows for 2 channel types",
x = "Length", y = "Density", color = "Channel Type" ) %>%
gf_theme(theme_bw)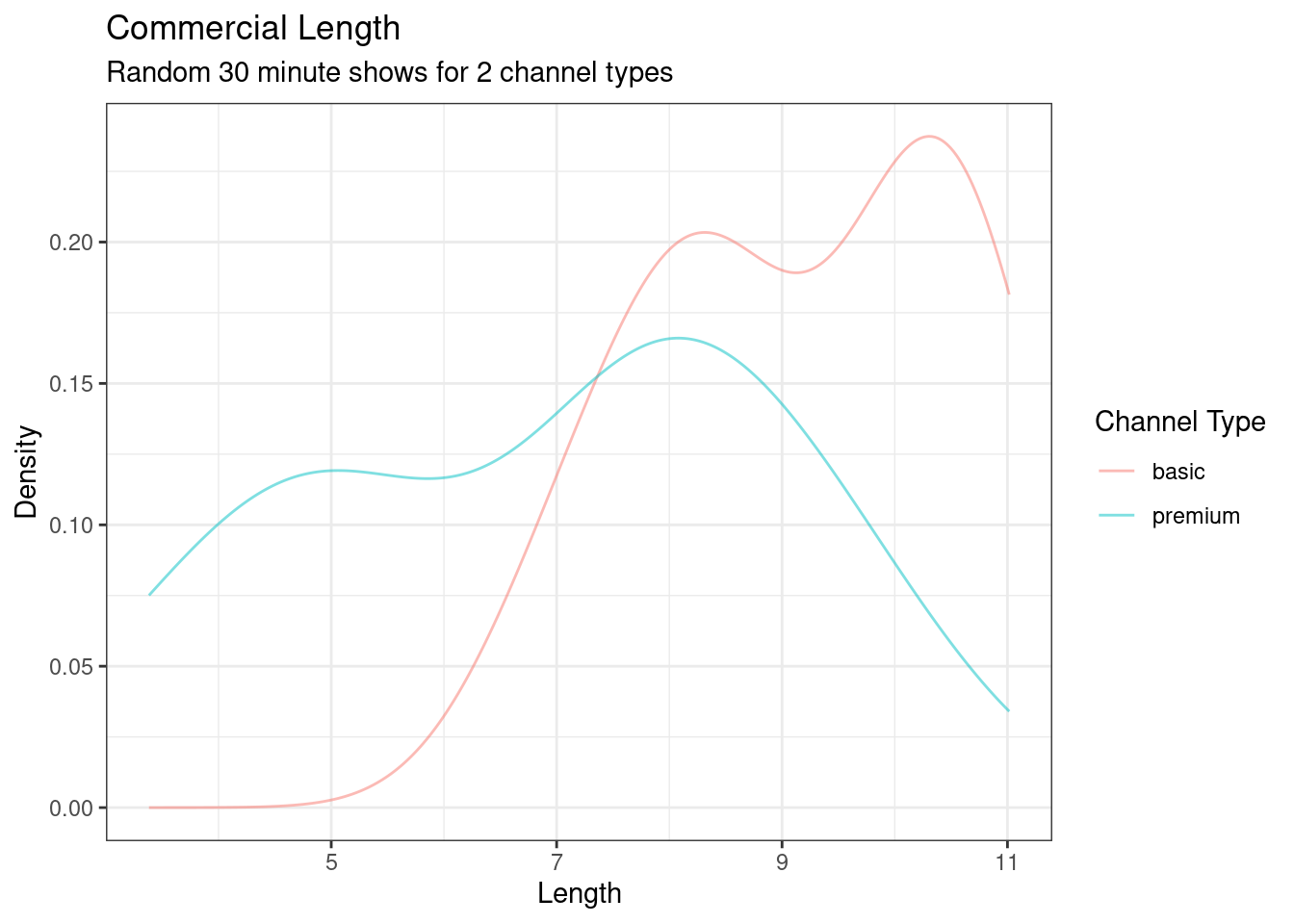
Figure 19.2: Commercial length broken down by channel type.
From this data, it looks like there is a difference between the two type of channels, but we must put the research question into a metric that will allow us to reach a decision. We will do this in a hypothesis test. As a reminder, the steps are
- State the null and alternative hypotheses.
- Compute a test statistic.
- Determine the \(p\)-value.
- Draw a conclusion.
Before doing this, let’s visit an example of hypothesis testing that has become common knowledge for us, the US criminal trial system. We could also use the cadet honor system. This analogy allows us to remember and apply the steps.
19.4.1 Hypothesis testing in the US court system
A US court considers two possible claims about a defendant: she is either innocent or guilty. Imagine you are the prosecutor. If we set these claims up in a hypothesis framework, the null hypothesis is that the defendant is innocent and the alternative hypothesis is that the defendant is guilty. Your job as the prosecutor is to use evidence to demonstrate to the jury that the alternative hypothesis is the reasonable conclusion.
The jury considers whether the evidence under the null hypothesis, innocence, is so convincing (strong) that there is no reasonable doubt regarding the person’s guilt. That is, the skeptical perspective (null hypothesis) is that the person is innocent until evidence is presented that convinces the jury that the person is guilty (alternative hypothesis).
Jurors examine the evidence under the assumption of innocence to see whether the evidence is so unlikely that it convincingly shows a defendant is guilty. Notice that if a jury finds a defendant not guilty, this does not necessarily mean the jury is confident in the person’s innocence. They are simply not convinced of the alternative that the person is guilty.
This is also the case with hypothesis testing: even if we fail to reject the null hypothesis, we typically do not accept the null hypothesis as truth. Failing to find strong evidence for the alternative hypothesis is not equivalent to providing evidence that the null hypothesis is true.
There are two types of mistakes possible in this scenario, letting a guilty person go free and sending an innocent person to jail. The criteria for making the decision, reasonable doubt, establishes the likelihood of those errors.
Now back to our problem.
19.4.2 Step 1- State the null and alternative hypotheses
The first step is to translate the research question into hypotheses. As a reminder, our research question is do premium channels have less ad time than basic channels? In collecting the data, we already decided the total length of time of commercials in a 30 minute show was the correct data for answering this question. We believe that premium channels have less commercial time. However, the null hypothesis, the straw man, has to be the default case that makes it possible to generate a sampling distribution.
- \(H_0\): Null hypothesis. The distribution of length of commercials for premium and basic channels is the same.
- \(H_A\): Alternative hypothesis. The distribution of length of commercials for premium and basic channels is different.
These hypotheses are vague. What does it mean for two distributions to be different and how do we measure and summarize this? Let’s move to the second step and then come back and modify our hypotheses. Notice that the null hypothesis states the distributions are the same. When we generate our sampling distribution of the test statistic, we will do so under this null hypothesis.
19.4.3 Step 2 - Compute a test statistic.
Exercise:
What type of metric could we use to test for a difference in the distributions of commercial lengths between the two types of channels?
There are many ways for the distributions of lengths of commercials to differ. The easiest is to think of the summary statistics such as mean, median, standard deviation, or some combination of all of these. Historically, for mathematical reasons, it has been common to look at differences in measures of centrality, mean or median. The second consideration is what kind of difference? For example, should we consider a ratio or an actual difference (subtraction)? Again for historical reasons, the difference in means has been used as a measure. To keep things interesting, and to force those with some high school stats experience to think about this problem differently, we are going to use a different metric than has historically been used and taught. This also requires us to write some of our own code. Later, we will ask you to complete the same analysis with a different test statistic, either with your own code or using code from the mosaic package.
Our metric is the ratio of the median length of commercials in basic channels to premium. Thus, our hypotheses are now:
\(H_0\): Null hypothesis. The distribution of length of commercials for premium and basic channels is the same.
\(H_A\): Alternative hypothesis. The distribution of length of commercials for premium and basic channels is different because the median length of basic channels ads is bigger than for premium channel ads.
First, let’s calculate the median length of commercials, by channel type, for our data.
median(length ~ channel, data = ads) ## basic premium
## 9.298 7.715So, the ratio of median lengths is
## basic
## 1.205185Let’s put the calculation of the ratio into a function.
metric(median(length ~ channel, data = ads))## test_stat
## 1.205185Now, let’s save the observed value of the test statistic in an object.
obs <- metric(median(length ~ channel, data = ads))
obs## test_stat
## 1.205185Here is what we have done; we needed a single number metric to use in evaluating the null and alternative hypotheses. The null hypothesis is that the commercial lengths for the two channel types have the same distribution and the alternative is that they don’t. To measure the alternative hypothesis, we decided to use a ratio of the medians. If the ratio is close to 1, then the medians are not different. There may be other ways in which the distributions are different but we have decided on the ratio of medians for this example.
19.4.4 Step 3 - Determine the \(p\)-value.
As a reminder, the \(p\)-value is the probability of our observed test statistic or something more extreme, given the null hypothesis is true. Since our null hypothesis is that the distributions are the same, we can use a randomization test. We will shuffle the channel labels since under the null hypothesis, they are irrelevant. Here is the code for one randomization.
## test_stat
## 0.9957097Let’s generate the empirical sampling distribution of the test statistic we developed. We will perform 1,000 simulations now.
Next we create a plot of the distribution of the ratio of median commercial lengths in basic and premium channels, assuming they come from the same population, Figure 19.3.
results %>%
gf_histogram(~test_stat) %>%
gf_vline(xintercept = obs) %>%
gf_theme(theme_bw()) %>%
gf_labs(x = "Test statistic")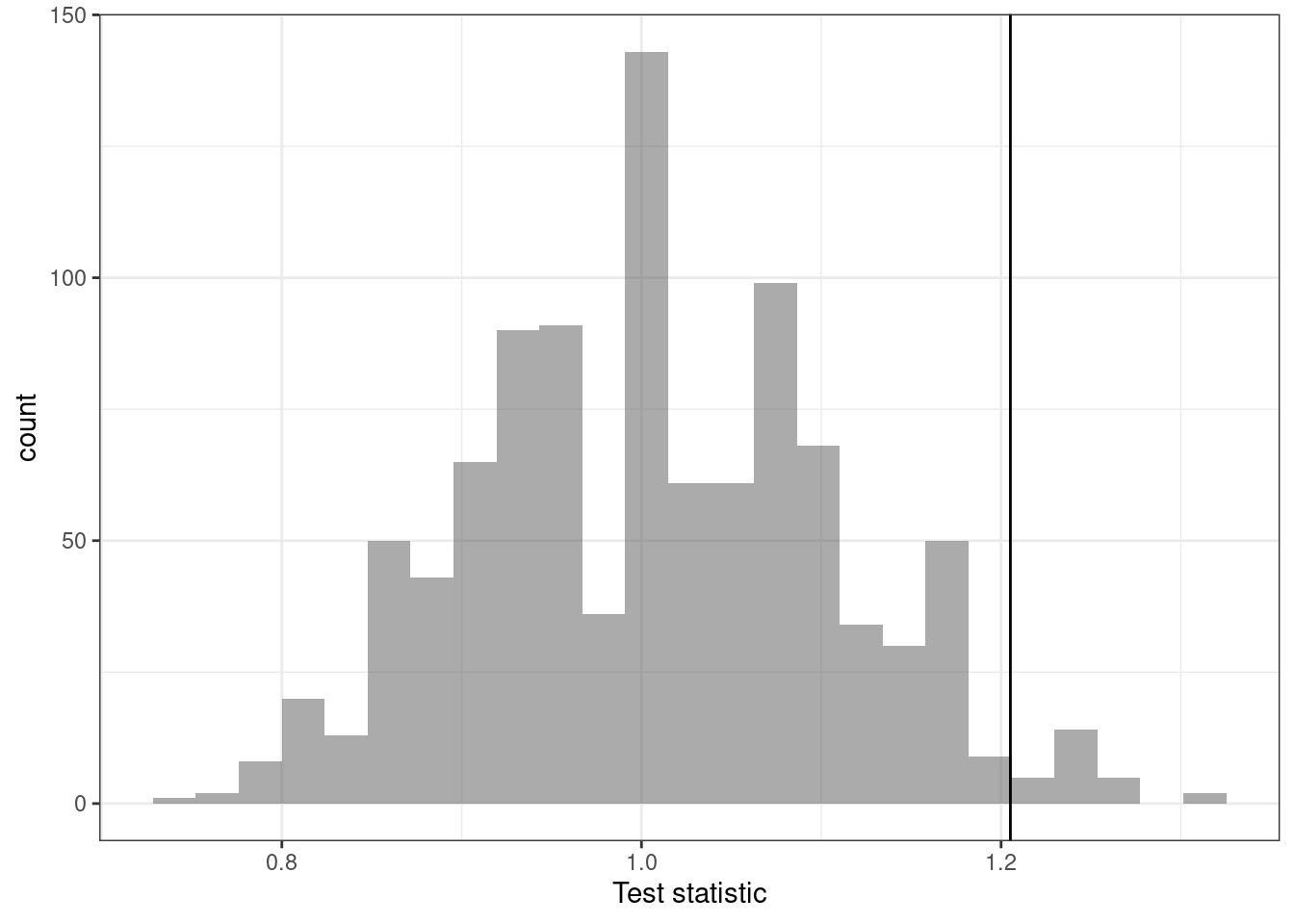
Figure 19.3: Historgram of the sampling distribution by an approxiamte permutation test
Notice that this distribution is centered on 1 and appears to be roughly symmetrical. The vertical line is our observed value of the test statistic. It seems to be in the tail, and is larger than expected if the channels came from the same distribution. Let’s calculate the \(p\)-value.
## p_value
## 1 0.026Before proceeding, we have a technical question: Should we include the observed data in the calculation of the \(p\)-value?
The answer is that most people would conclude that the original data is one of the possible permutations and thus include it. This practice will also ensure that the \(p\)-value from a randomization test is never zero. In practice, this simply means adding 1 to both the numerator and denominator. The mosaic package has done this for us with the prop1() function.
prop1(~(test_stat >= obs), data = results)## prop_TRUE
## 0.02697303The test we performed is called a one-sided test because we only checked if the median length for basic channels is larger than that for premium channels. In this case of a one-sided test, more extreme meant a ratio much bigger than 1. A two-sided test is also common, in fact it is more common, and is used if we did not apriori think one channel type had longer commercials than the other. In this case, we find the \(p\)-value by doubling the single-sided value. This is because more extreme could have happened in either tail of the sampling distribution.
19.4.5 Step 4 - Draw a conclusion
Our research question – do premium channels have less ad time than basic channels? – was framed in context of the following hypotheses:
\(H_0\): Null hypothesis. The distribution of length of commercials for premium and basic channels is the same.
\(H_A\): Alternative hypothesis. The distribution of length of commercials for premium and basic channels is different because the median length of basic channels ads is bigger than for premium channel ads.
In our simulations, less than 2.7% of the simulated test statistics were greater than or equal (more extreme relative to the null hypothesis) to the observed test statistic. That is, the observed ratio of 1.2 is a rare event if the distributions of commercial lengths for premium and basic channels truly are the same. By chance alone, we would only expect an observed ratio this large to occur less than 3 in 100 times. When results like these are inconsistent with \(H_0\), we reject \(H_0\) in favor of \(H_A\). Here, we reject \(H_0\) and conclude there is evidence that the median length of basic channel ads is bigger than that for premium channels.
The less than 3-in-100 chance is the \(p\)-value, which is a probability quantifying the strength of the evidence against the null hypothesis and in favor of the alternative.
When the \(p\)-value is small, i.e. less than a previously set threshold, we say the results are statistically significant84. This means the data provide such strong evidence against \(H_0\) that we reject the null hypothesis in favor of the alternative hypothesis. The threshold, called the significance level and often represented by the Greek letter \(\alpha\), is typically set to \(\alpha = 0.05\), but can vary depending on the field or the application. Using a significance level of \(\alpha = 0.05\) in the TV channel study, we can say that the data provided statistically significant evidence against the null hypothesis.
We say that the data provide statistically significant evidence against the null hypothesis if the \(p\)-value is less than some reference value, usually \(\alpha=0.05\).
If the null hypothesis is true, unknown to us, the significance level \(\alpha\) defines the probability that we will make a Type 1 Error. We will define decision errors in the next section.
Side note: What’s so special about 0.05? We often use a threshold of 0.05 to determine whether a result is statistically significant. But why 0.05? Maybe we should use a bigger number, or maybe a smaller number. If you’re a little puzzled, that probably means you’re reading with a critical eye – good job! There are many video clips that explain the use of 0.05. Sometimes it’s also a good idea to deviate from the standard. It really depends on the risk that the decision maker wants to accept in terms of the two types of decision errors.
Exercise:
Use our \(p\)-value and a significance level of 0.05 to make a decision.
Based on our data, if there were really no difference in the distribution of lengths of commercials in 30 minute shows between basic and premium channels then the probability of finding our observed ratio of medians is 0.027. Since this is less than our significance level of \(\alpha = 0.05\), we reject the null in favor of the alternative that the basic channel has longer commercials.
19.4.6 Decision errors
Hypothesis tests are not flawless. Just think of the court system: innocent people are sometimes wrongly convicted and the guilty sometimes walk free. Similarly, data can point to the wrong conclusion. However, what distinguishes statistical hypothesis tests from a court system is that our framework allows us to quantify and control how often the data lead us to the incorrect conclusion.
There are two competing hypotheses: the null and the alternative. In a hypothesis test, we make a statement about which one might be true, but we might choose incorrectly. There are four possible scenarios in a hypothesis test, which are summarized below.
\[ \begin{array}{cc|cc} & & \textbf{Test Conclusion} &\\ & & \text{do not reject } H_0 & \text{reject } H_0 \text{ in favor of }H_A \\ \textbf{Truth} & \hline H_0 \text{ true} & \text{Correct Decision} & \text{Type 1 Error} \\ & H_A \text{true} & \text{Type 2 Error} & \text{Correct Decision} \\ \end{array} \]
A Type 1 error, also called a false positive, is rejecting the null hypothesis when \(H_0\) is actually true. Since we rejected the null hypothesis in the gender discrimination (from the Case Study) and the commercial length studies, it is possible that we made a Type 1 error in one or both of those studies. A Type 2 error, also called a false negative, is failing to reject the null hypothesis when the alternative is actually true. A Type 2 error was not possible in the gender discrimination or commercial length studies because we rejected the null hypothesis.
Example:
In a US court, the defendant is either innocent (\(H_0\)) or guilty (\(H_A\)). What does a Type 1 error represent in this context? What does a Type 2 error represent?
If the court makes a Type 1 error, this means the defendant is truly innocent (\(H_0\) true) but is wrongly convicted. A Type 2 error means the court failed to reject \(H_0\) (i.e. failed to convict the person) when she was in fact guilty (\(H_A\) true).
Exercise:
Consider the commercial length study where we concluded basic channels had longer commercials than premium channels. What would a Type 1 error represent in this context?85
Exercise:
How could we reduce the Type 1 error rate in US courts? What influence would this have on the Type 2 error rate?
To lower the Type 1 error rate, we might raise our standard for conviction from “beyond a reasonable doubt” to “beyond a conceivable doubt” so fewer people would be wrongly convicted. However, this would also make it more difficult to convict the people who are actually guilty, so we would make more Type 2 errors.
Exercise:
How could we reduce the Type 2 error rate in US courts? What influence would this have on the Type 1 error rate?
To lower the Type 2 error rate, we want to convict more guilty people. We could lower the standards for conviction from “beyond a reasonable doubt” to “beyond a little doubt”. Lowering the bar for guilt will also result in more wrongful convictions, raising the Type 1 error rate.
Exercise: Think about the cadet honor system, its metric of evaluation, and the impact on the types of decision errors.
These exercises provide an important lesson: if we reduce how often we make one type of error, we generally make more of the other type for a given amount of data, information.
19.4.7 Choosing a significance level
Choosing a significance level for a test is important in many contexts, and the traditional level is \(\alpha = 0.05\). However, it is sometimes helpful to adjust the significance level based on the application. We may select a level that is smaller or larger than 0.05 depending on the consequences of any conclusions reached from the test.
If making a Type 1 error is dangerous or especially costly, we should choose a small significance level (e.g. 0.01 or 0.001). Under this scenario, we want to be very cautious about rejecting the null hypothesis, so we demand very strong evidence favoring the alternative \(H_A\) before we would reject \(H_0\).
If making a Type 2 error is relatively more dangerous or much more costly than a Type 1 error, then we should choose a higher significance level (e.g. 0.10). Here we want to be cautious about failing to reject \(H_0\) when the null hypothesis is actually false.
The significance level selected for a test should reflect the real-world consequences associated with making a Type 1 or Type 2 error.
19.4.8 Introducing two-sided hypotheses
So far we have explored whether women were discriminated against and whether commercials were longer depending on the type of channel. In these two case studies, we’ve actually ignored some possibilities:
- What if men are actually discriminated against?
- What if ads on premium channels are actually longer?
These possibilities weren’t considered in our hypotheses or analyses. This may have seemed natural since the data pointed in the directions in which we framed the problems. However, there are two dangers if we ignore possibilities that disagree with our data or that conflict with our worldview:
- Framing an alternative hypothesis simply to match the direction that the data point will generally inflate the Type 1 error rate. After all the work we’ve done (and will continue to do) to rigorously control the error rates in hypothesis tests, careless construction of the alternative hypotheses can disrupt that hard work.
- If we only use alternative hypotheses that agree with our worldview, then we’re going to be subjecting ourselves to confirmation bias, which means we are looking for data that supports our ideas. That’s not very scientific, and we can do better!
The previous hypothesis tests we’ve seen are called one-sided hypothesis tests because they only explored one direction of possibilities. Such hypotheses are appropriate when we are exclusively interested in a single direction, but usually we want to consider all possibilities. To do so, let’s discuss two-sided hypothesis tests in the context of a new study that examines the impact of using blood thinners on patients who have undergone cardiopulmonary resuscitation, CPR.
19.5 Two-sided hypothesis test
It is important to distinguish between a two-sided hypothesis test and a one-sided hypothesis test. In a two-sided test, we are concerned with whether or not the population parameter could take a particular value. For parameter \(\theta\), a set of two-sided hypotheses looks like:
\[ H_0: \theta=\theta_0 \hspace{1.5cm} H_1: \theta \neq \theta_0 \] where \(\theta_0\) is a particular value the parameter could take on.
In a one-sided test, we are concerned with whether a parameter exceeds or does not exceed a specific value. A set of one-sided hypotheses looks like:
\[ H_0: \theta = \theta_0 \hspace{1.5cm} H_1:\theta > \theta_0 \] or
\[ H_0: \theta = \theta_0 \hspace{1.5cm} H_1:\theta < \theta_0 \]
In some texts, one-sided null hypotheses include an inequality (\(H_0 \leq \theta_0\) or \(H_0 \geq \theta_0\)). We have already demonstrated one-sided tests and, in the next example, we will use a two-sided test.
19.5.1 CPR example
Cardiopulmonary resuscitation (CPR) is a procedure used on individuals suffering a heart attack when other emergency resources are unavailable. This procedure is helpful in providing some blood circulation to keep a person alive, but CPR chest compressions can also cause internal injuries. Internal bleeding and other injuries that can result from CPR complicate additional treatment efforts. For instance, blood thinners may be used to help release a clot that is causing the heart attack once a patient arrives in the hospital. However, blood thinners negatively affect internal injuries.
Here we consider an experiment with patients who underwent CPR for a heart attack and were subsequently admitted to a hospital.86 Each patient was randomly assigned to either receive a blood thinner (treatment group) or not receive a blood thinner (control group). The outcome variable of interest was whether the patient survived for at least 24 hours.
19.5.2 Step 1 - State the null and alternative hypotheses
Exercise: Form hypotheses for this study in plain and statistical language. Let \(p_c\) represent the true survival rate of people who do not receive a blood thinner (corresponding to the control group) and \(p_t\) represent the survival rate for people receiving a blood thinner (corresponding to the treatment group).
We want to understand whether blood thinners are helpful or harmful. We’ll consider both of these possibilities using a two-sided hypothesis test.
\(H_0\): Blood thinners do not have an overall survival effect; survival rate is independent of experimental treatment group. \(p_c - p_t = 0\).
\(H_A\): Blood thinners have an impact on survival, either positive or negative, but not zero. \(p_c - p_t \neq 0\).
Notice here that we accelerated the process by already defining our test statistic, our metric, in the hypothesis. It is the difference in survival rates for the control and treatment groups. This is a similar metric to what we used in the case study. We could use others but this will allow us to use functions from the mosaic package and will also help us to understand metrics for mathematically derived sampling distributions.
There were 50 patients in the experiment who did not receive a blood thinner and 40 patients who did. The study results are in the file blood_thinner.csv.
thinner <- read_csv("data/blood_thinner.csv")
thinner## # A tibble: 90 × 2
## group outcome
## <chr> <chr>
## 1 treatment survived
## 2 control survived
## 3 control died
## 4 control died
## 5 control died
## 6 treatment survived
## 7 control died
## 8 control died
## 9 treatment died
## 10 treatment survived
## # ℹ 80 more rowsLet’s put the data in a table.
tally(~group + outcome, data = thinner, margins = TRUE)## outcome
## group died survived Total
## control 39 11 50
## treatment 26 14 40
## Total 65 25 9019.5.3 Step 2 - Compute a test statistic.
The test statistic we have selected is the difference in survival rate between the control group and the treatment group. The following R command finds the observed proportions.
tally(outcome ~ group, data = thinner, margins = TRUE, format = "proportion")## group
## outcome control treatment
## died 0.78 0.65
## survived 0.22 0.35
## Total 1.00 1.00Notice the formula we used to get the correct variable in the column for the summary proportions.
The observed test statistic can now be found.87
obs <- diffprop(outcome ~ group, data = thinner)
obs## diffprop
## -0.13Based on the point estimate, for patients who have undergone CPR outside of the hospital, an additional 13% of these patients survive when they are treated with blood thinners. We wonder if this difference is easily explainable by chance.
19.5.4 Step 3 - Determine the \(p\)-value.
As we did in the previous two studies, we will simulate what type of differences we might see from chance alone under the null hypothesis. By randomly assigning treatment and control stickers to the patients’ files, we get a new grouping. If we repeat this simulation 10,000 times, we can build a null distribution of the differences. This is our empirical sampling distribution, the distribution of differences simulated under the null hypothesis.
Figure 19.4 is a histogram of the estimated sampling distribution.
results %>%
gf_histogram(~diffprop) %>%
gf_vline(xintercept = obs) %>%
gf_theme(theme_bw()) %>%
gf_labs(x = "Test statistic")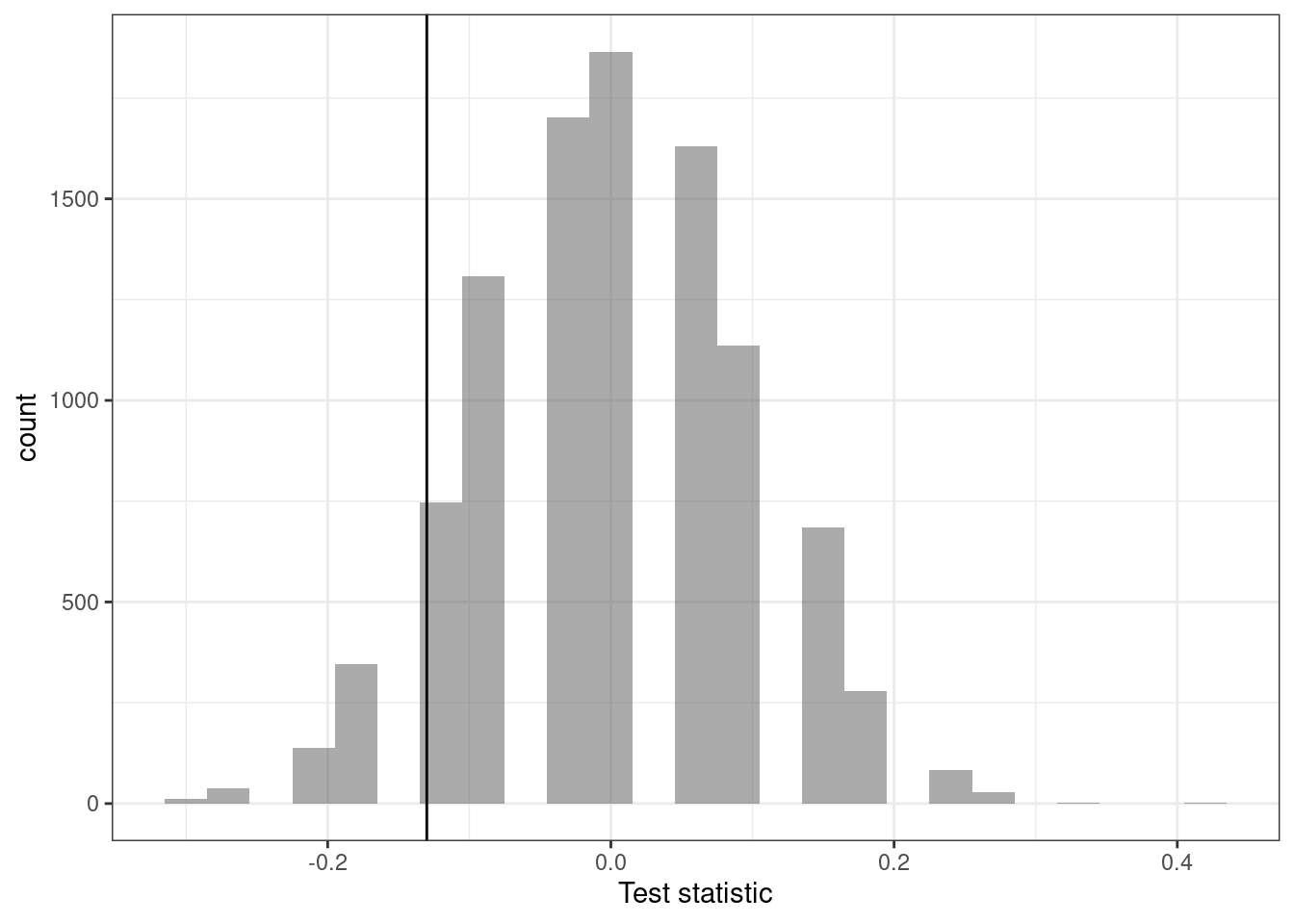
Figure 19.4: Histogram of the estimated sampling distribution.
Notice how it is centered on zero, the assumption of no difference. Also notice that it is unimodal and symmetric. We will use this when we develop mathematical sampling distributions. We now calculate the proportion of simulated differences that are less than or equal to the observed difference.
prop1(~(diffprop <= obs), data = results)## prop_TRUE
## 0.1283872The left tail area is about 0.128. (Note: it is only a coincidence that our \(p\)-value is approximately 0.13 and we also have \(\hat{p}_c - \hat{p}_t= -0.13\).) However, contrary to how we calculated the \(p\)-value in previous studies, the \(p\)-value of this test is not 0.128!
The \(p\)-value is defined as the probability we observe a result at least as favorable to the alternative hypothesis as the observed result (i.e. the observed difference). In this case, any differences greater than or equal to 0.13 would provide equally strong evidence favoring the alternative hypothesis as differences less than or equal to -0.13. A difference of 0.13 would correspond to 13% higher survival rate in the treatment group than the control group.
There is something different in this study than in the past studies: in this study, we are particularly interested in whether blood thinners increase or decrease the risk of death in patients who undergo CPR before arriving at the hospital.88
For a two-sided test, we take the single tail (in this case, 0.128) and double it to get the \(p\)-value: 0.256.
19.5.5 Step 4 - Draw a conclusion
Since this \(p\)-value is larger than 0.05, we fail to reject the null hypothesis. That is, we do not find statistically significant evidence that the blood thinner has any influence on survival of patients who undergo CPR prior to arriving at the hospital. Once again, we can discuss the causal conclusion since this is an experiment.
Default to a two-sided test We want to be rigorous and keep an open mind when we analyze data and evidence. In general, you should default to using a two-sided test when conducting hypothesis tests. Use a one-sided hypothesis test only if you truly have interest in only one direction.
Computing a \(p\)-value for a two-sided test
First compute the \(p\)-value for one tail of the distribution, then double that value to get the two-sided \(p\)-value. That’s it!
It is never okay to change two-sided tests to one-sided tests after observing the data.
Hypothesis tests should be set up before seeing the data
After observing data, it can be tempting to turn a two-sided test into a one-sided test. Avoid this temptation. Hypotheses and the significance level should be set up before observing the data.
19.5.6 How to use a hypothesis test
This is a summary of the general framework for using hypothesis testing. These are the same steps as before, with just slightly different wording.
-
Frame the research question in terms of hypotheses.
Hypothesis tests are appropriate for research questions that can be summarized in two competing hypotheses. The null hypothesis (\(H_0\)) usually represents a skeptical perspective or a perspective of no difference. The alternative hypothesis (\(H_A\)) usually represents a new view or a difference.
-
Collect data with an observational study or experiment.
If a research question can be formed into two hypotheses, we can collect data to run a hypothesis test. If the research question focuses on associations between variables but does not concern causation, we would run an observational study. If the research question seeks a causal connection between two or more variables, then an experiment should be used if possible.
-
Analyze the data.
Choose an analysis technique appropriate for the data and identify the \(p\)-value. So far, we’ve only seen one analysis technique: randomization. We’ll encounter several new methods suitable for many other contexts.
-
Form a conclusion.
Using the \(p\)-value from the analysis, determine whether the data provide statistically significant evidence against the null hypothesis. Also, be sure to write the conclusion in plain language so casual readers can understand the results.
19.6 Homework Problems
- Repeat the analysis of the commercial lengths for basic and premium TV channels in the notes. This time, use a different test statistic.
State the null and alternative hypotheses.
Compute a test statistic. Remember to use something different than what was used in the text.
Determine the \(p\)-value.
Draw a conclusion.
- Is yawning contagious?
An experiment conducted by the MythBusters, a science entertainment TV program on the Discovery Channel, tested whether a person can be subconsciously influenced into yawning if another person near them yawns. 50 people were randomly assigned to two groups: 34 to a group where a person near them yawned (treatment) and 16 to a group where there wasn’t a person yawning near them (control). The following table shows the results of this experiment.
\[ \begin{array}{cc|ccc} & & &\textbf{Group}\\ & & \text{Treatment } & \text{Control} & \text{Total} \\ & \hline \text{Yawn} & 10 & 4 & 14 \\ \textbf{Result} & \text{Not Yawn} & 24 & 12 & 36 \\ &\text{Total} & 34 & 16 & 50 \\ \end{array} \]
The data is in the file yawn.csv.
What are the hypotheses?
Calculate the observed difference between the yawning rates under the two scenarios. Yes, we are giving you the test statistic.
Estimate the \(p\)-value using randomization.
Plot the empirical sampling distribution.
Determine the conclusion of the hypothesis test.
The traditional belief is that yawning is contagious – one yawn can lead to another yawn, which might lead to another, and so on. In this exercise, there was the option of selecting a one-sided or two-sided test. Which would you recommend (or which did you choose)? Justify your answer in 1-3 sentences.
How did you select your level of significance? Explain in 1-3 sentences.