22 Confidence Intervals
22.1 Objectives
Using asymptotic methods based on the normal distribution, construct and interpret a confidence interval for an unknown parameter.
Describe the relationships between confidence intervals, confidence level, and sample size.
Describe the relationships between confidence intervals and hypothesis testing.
Calculate confidence intervals for proportions using three different approaches in
R: explicit calculation,binom.test(), andprop_test().
22.2 Confidence intervals
A point estimate provides a single plausible value for a parameter. However, a point estimate is rarely perfect; usually there is some error in the estimate. In addition to supplying a point estimate of a parameter, the next logical step would be to provide a plausible range of values for the parameter.
22.2.1 Capturing the population parameter
A plausible range of values for the population parameter is called a confidence interval. Using only a point estimate is like fishing in a murky lake with a spear, and using a confidence interval is like fishing with a net. We can throw a spear where we saw a fish, but we will probably miss. On the other hand, if we toss a net in that area, we have a good chance of catching the fish.
If we report a point estimate, we probably will not hit the exact population parameter. On the other hand, if we report a range of plausible values – a confidence interval – we have a good shot at capturing the parameter.
Exercise: If we want to be very certain we capture the population parameter, should we use a wider interval or a smaller interval?101
22.2.2 Constructing a confidence interval
The general formula for constructing a confidence interval is
\[\text{point estimate} \ \pm\ \text{critical value}\times \text{standard error}\]
A point estimate is our best guess for the value of the population parameter, so it makes sense to build the confidence interval around that value. The standard error, which is a measure of the uncertainty associated with the point estimate, provides a guide for how large we should make the confidence interval. The critical value is the number of standard deviations needed for the confidence interval.
Generally, what you should know about building confidence intervals is laid out in the following steps:
Identify the parameter you would like to estimate (e.g., the population mean, \(\mu\)).
Identify a good estimate for that parameter (e.g., the sample mean, \(\bar{X}\)).
Determine the distribution of your estimate, or a function of your estimate.
Use this distribution to obtain a range of feasible values (a confidence interval) for the parameter. (For example, if \(\mu\) is the parameter of interest and we are using the CLT, then \(\frac{\bar{X} - \mu}{\sigma/\sqrt{n}}\sim \textsf{Norm}(0,1)\). We can solve this equation for \(\mu\) to find a range of feasible values.)
Constructing a 95% confidence interval When the sampling distribution of a point estimate can reasonably be modeled as normal, the point estimate we observe will be within 1.96 standard errors of the true value of interest about 95% of the time. Thus, a 95% confidence interval for such a point estimate can be constructed as
\[ \hat{\theta} \pm\ 1.96 \times SE_{\hat{\theta}},\] where \(\hat{\theta}\) is our estimate of the parameter and \(SE_{\hat{\theta}}\) is the standard error of that estimate.
We can be 95% confident this interval captures the true value of the parameter. The number of standard errors to include in the interval (e.g., 1.96) can be found using the qnorm() function. Note that the qnorm() function calculates the lower tail quantile of a standard normal distribution by default. If we want 0.95 probability in the middle, that leaves 0.025 in each tail. Thus, we use 0.975 in the qnorm() function for a 95% confidence interval.
qnorm(.975)## [1] 1.959964Exercise:
Compute the area between -1.96 and 1.96 for a normal distribution with mean 0 and standard deviation 1.
## [1] 0.9500042In mathematical terms, the derivation of this confidence interval is as follows:
Let \(X_1, X_2, ..., X_n\) be an i.i.d. sequence of random variables, each with mean \(\mu\) and standard deviation \(\sigma\). The central limit theorem tells us that
\[ \bar{X} \overset{approx} {\sim}\textsf{Norm}\left(\mu, {\sigma\over\sqrt{n}}\right) \]
and, thus,
\[ \frac{\bar{X} - \mu}{\sigma/\sqrt{n}} \overset{approx} {\sim}\textsf{Norm}(0, 1) \]
If the significance level is \(0\leq \alpha \leq 1\), then the confidence level is \(1 - \alpha\). The \(\alpha\) value here is the same as the significance level in hypothesis testing. Thus,
\[ \mbox{P}\left(-z_{\alpha/2} \leq {\bar{X} - \mu\over \sigma/\sqrt{n}} \leq z_{\alpha/2}\right) = 1 - \alpha \]
where \(z_{\alpha/2}\) is such that \(\mbox{P}(Z\geq z_{\alpha/2}) = \alpha/2\), where \(Z\sim \textsf{Norm}(0,1)\). See Figure 22.1 for an illustration.
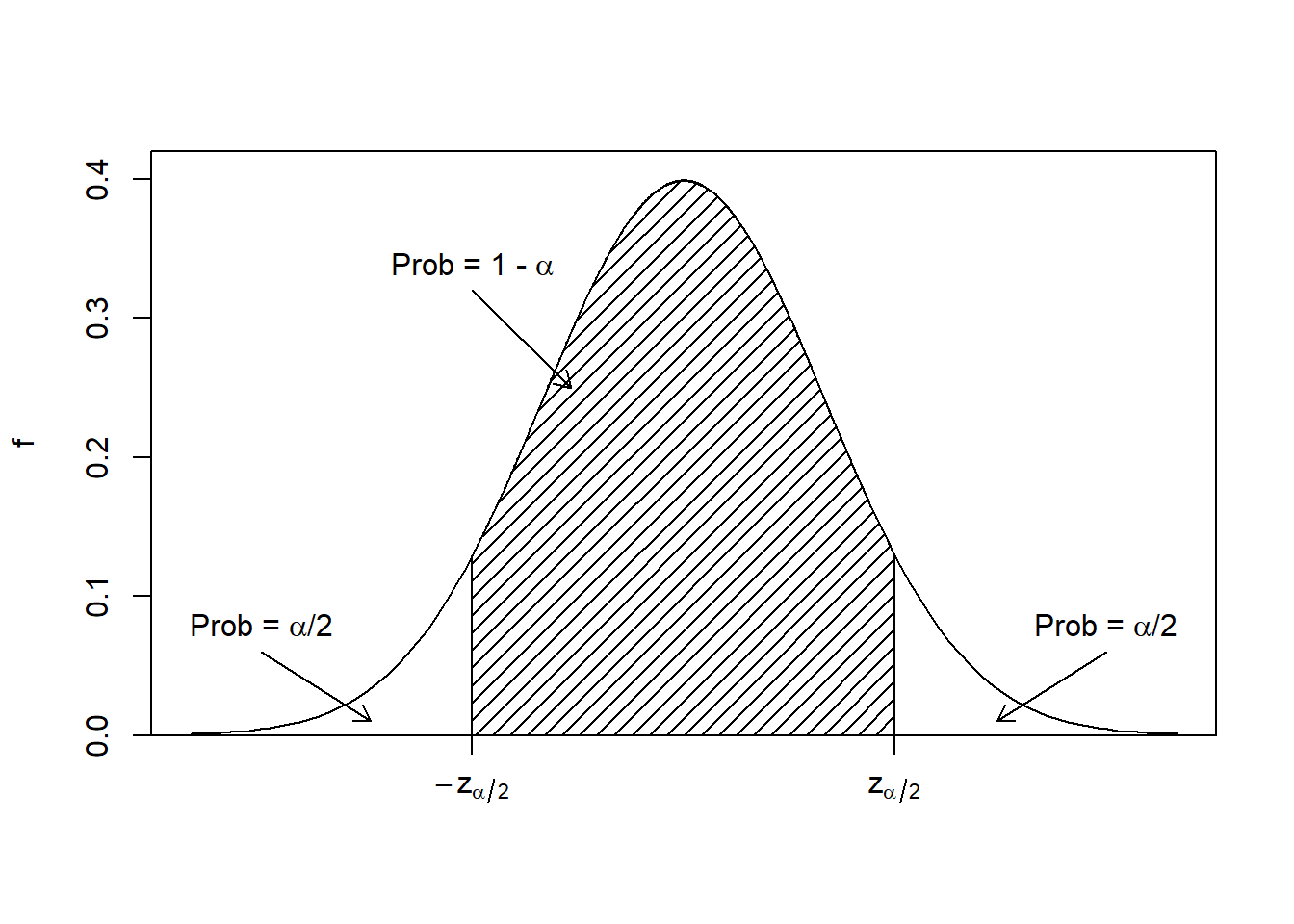
Figure 22.1: The pdf of a standard normal distribution, showing the idea of how to develop a confidence interval.
So, we know that \((1 - \alpha)*100\%\) of the time, \({\bar{X} - \mu\over \sigma/\sqrt{n}}\) will be between \(-z_{\alpha/2}\) and \(z_{\alpha/2}\).
By rearranging the probability expression above and solving for \(\mu\), we get:
\[ \mbox{P}\left(\bar{X} - z_{\alpha/2}{\sigma\over\sqrt{n}} \leq \mu \leq \bar{X} + z_{\alpha/2}{\sigma \over \sqrt{n}}\right) = 1 - \alpha \]
Be careful with the interpretation of this expression. As a reminder, \(\bar{X}\) is the random variable here. The population mean, \(\mu\), is NOT a variable. It is an unknown parameter. Thus, the above expression is NOT a probabilistic statement about \(\mu\). It is a probabilistic statement about the random variable \(\bar{X}\).
Nonetheless, the above expression gives us a nice interval, a range of “reasonable” values of \(\mu\), given a particular sample.
A \((1 - \alpha)*100\%\) confidence interval for the mean is given by:
\[ \mu \in \left(\bar{x} \pm z_{\alpha/2} {\sigma\over\sqrt{n}} \right) \]
Notice in this equation that we are using the lower case \(\bar{x}\), the observed sample mean, and thus nothing is random in the interval. Thus, we will not use probabilistic statements about confidence intervals when we calculate numerical values from data for the upper and/or lower limits.
In most applications, the most common value of \(\alpha\) is 0.05. In that case, we construct a 95% confidence interval by finding \(z_{0.05/2} = z_{0.025}\) or \(z_{1 - 0.05/2} = z_{0.975}\), which can be found easily with qnorm():
qnorm(1 - 0.05/2)## [1] 1.959964
qnorm(.975)## [1] 1.959964Notice that we prefer to use the upper tail probability so that quantile values are positive.
qnorm(0.025)## [1] -1.959964The value of \(z_{0.025}\) is negative; this requires a little more care when calculating the confidence interval due to changing signs. We recommend always using the upper tail probability for this reason.
22.2.2.1 Unknown Variance
When inferring about the population mean, we will usually have to estimate the underlying, population, standard deviation \(\sigma\) as well. We usually estimate \(\sigma\) with \(S\), the sample standard deviation. This introduces an extra level of uncertainty to the confidence interval. We found that while \({\bar{X} - \mu \over \sigma/\sqrt{n}}\) has an approximate normal distribution, \({\bar{X} - \mu\over S/\sqrt{n}}\) follows the \(t\)-distribution with \(n - 1\) degrees of freedom. This requires the additional assumption that the parent population, the distribution of \(X\), is normal.
Thus, when \(\sigma\) is unknown, a \((1 - \alpha)*100\%\) confidence interval for the mean is given by:
\[ \mu \in \left(\bar{x} \pm t_{\alpha/2, n - 1}{s \over \sqrt{n}} \right) \]
Similar to what was done previously, \(t_{\alpha/2, n - 1}\) can be found using the qt() function in R.
In practice, if the underlying distribution of \(X\) is close to symmetrical and unimodal, we can relax the assumption of normality. Always look at your sample data though. Outliers or skewness can be causes of concern. We can always use other methods to find confidence intervals that don’t require the assumption of normality and compare results. We’ll talk more about some of these methods in the next chapter.
For large sample sizes, the choice of using the normal distribution or the \(t\) distribution is irrelevant because they are very similar to each other. The \(t\) distribution requires us to use the degrees of freedom though, so be careful.
22.2.3 Body Temperature Example
Example:
Find a 95% confidence interval for the body temperature data from Chapter 19.
We need the mean, standard deviation, and sample size from this data. We can find those values using favstats(). The following R code calculates the confidence interval, using the values from favstats() and the expression for a 95% confidence interval given above. Make sure you can follow the code. It can usually help to to run the code line-by-line (i.e., run the first two lines only, then the first three lines only, and so on).
temperature %>%
favstats(~temperature, data = .) %>%
select(mean, sd, n) %>%
summarize(lower_bound = mean - qt(0.975, 129)*sd/sqrt(n),
upper_bound = mean + qt(0.975, 129)*sd/sqrt(n))## lower_bound upper_bound
## 1 98.122 98.37646The 95% confidence interval for \(\mu\) is \((98.12, 98.38)\). We are 95% confident that \(\mu\), the average human body temperature, is in this interval. Alternatively and equally relevant, we could say that 95% of similarly constructed intervals will contain the true mean, \(\mu\). It is important to understand the use of the word confident and not the word probability.
As a reminder, we need to be careful with the interpretation of the confidence interval. We have found the interval by calculating numerical values from the observed data, and thus nothing in the interval is random. Thus, we will not make statements about probability once we have calculated the interval. We will only make statements about confidence.
Important Note: There is a link between hypothesis testing and confidence intervals. A confidence interval provides us with a range of feasible values for the parameter. In hypothesis testing, we are trying to determine whether the null hypothesized value is a feasible value of the parameter. Remember when we used the body temperature data in a hypothesis test, the null hypothesis was \(H_0\): The average body temperature is 98.6 degrees Fahrenheit, \(\mu = 98.6\). This null hypothesized value is not inside the interval, so we could reject the null hypothesis with this confidence interval and conclude that 98.6 degrees is not a feasible value of the true mean body temperature.
We could also use R to find the confidence interval and conduct the hypothesis test. Notice that the connection between confidence intervals and hypothesis testing is reinforced here; we can use the t_test() function to conduct a \(t\)-test and to calculate a confidence interval. Read about the function t_test() in the help menu to determine why we used the mu option.
t_test(~temperature, data = temperature, mu = 98.6)##
## One Sample t-test
##
## data: temperature
## t = -5.4548, df = 129, p-value = 2.411e-07
## alternative hypothesis: true mean is not equal to 98.6
## 95 percent confidence interval:
## 98.12200 98.37646
## sample estimates:
## mean of x
## 98.24923We can use the following code if we only want the interval:
## mean of x lower upper level
## 1 98.24923 98.122 98.37646 0.95In reviewing the hypothesis test for a single mean, you can see how this confidence interval was formed by inverting the test statistic, \({\bar{X} - \mu\over \sigma/\sqrt{n}}\). As a reminder, the following equation inverts the test statistic.
\[ \mbox{P}\left(\bar{X}-z_{\alpha/2}{\sigma\over\sqrt{n}}\leq \mu \leq \bar{X}+z_{\alpha/2}{\sigma\over\sqrt{n}}\right)=1-\alpha \]
22.2.4 One-sided Intervals
If you remember the hypothesis test for body temperature in Chapter 19 on the central limit theorem, you may be crying foul. That was a one-sided hypothesis test and we just conducted a two-sided test. So far, we have discussed only “two-sided” intervals. These intervals have an upper and lower bound. Typically, \(\alpha\) is apportioned equally between the two tails. (Thus, we look for \(z_{\alpha/2}\) or \(z_{1 - \alpha/2}\).)
In “one-sided” intervals, we only bound the interval on one side, providing only an upper bound or only a lower bound. We construct one-sided intervals when we are concerned with whether a parameter exceeds or stays below some threshold. Building a one-sided interval is similar to building two-sided intervals, but rather than dividing \(\alpha\) into two, we simply apportion all of \(\alpha\) to the relevant side. The difficult part is in determining whether we need an upper bound or lower bound.
For the body temperature study, the alternative hypothesis was that the mean body temperature was less than 98.6. We are trying to reject the null hypothesis by showing an alternative that is smaller than the null hypothesized value. Finding the lower limit does not help us because the confidence interval indicates an interval that starts at the lower value and is unbounded above. Let’s just make up some numbers to help illustrate this. Suppose the lower confidence bound is 97.5. All we know is that the true average temperature is 97.5 or greater. This is not helpful in determining whether the true average temperature is less than 98.6. However, if we find an upper confidence bound and the value is 98.1, we know the true average temperature is most likely no larger than this value, and hence, is less than 98.6. This is much more helpful. In our confidence interval, we want to find the largest value the mean could reasonably be and, thus, we want the upper bound.
We now repeat the analysis with this in mind.
temperature %>%
favstats(~temperature, data = .) %>%
select(mean, sd, n) %>%
summarize(upper_bound = mean + qt(0.95, 129)*sd/sqrt(n))## upper_bound
## 1 98.35577## mean of x lower upper level
## 1 98.24923 -Inf 98.35577 0.95Notice that the probability in qt() has been adjusted to calculate \(t_{1 - \alpha}\). Additionally, the upper bound in the one-sided interval is smaller than the upper bound in the two-sided interval because all 0.05 is going into the upper tail. See Figure 22.2 for an illustration of a one-sided interval.
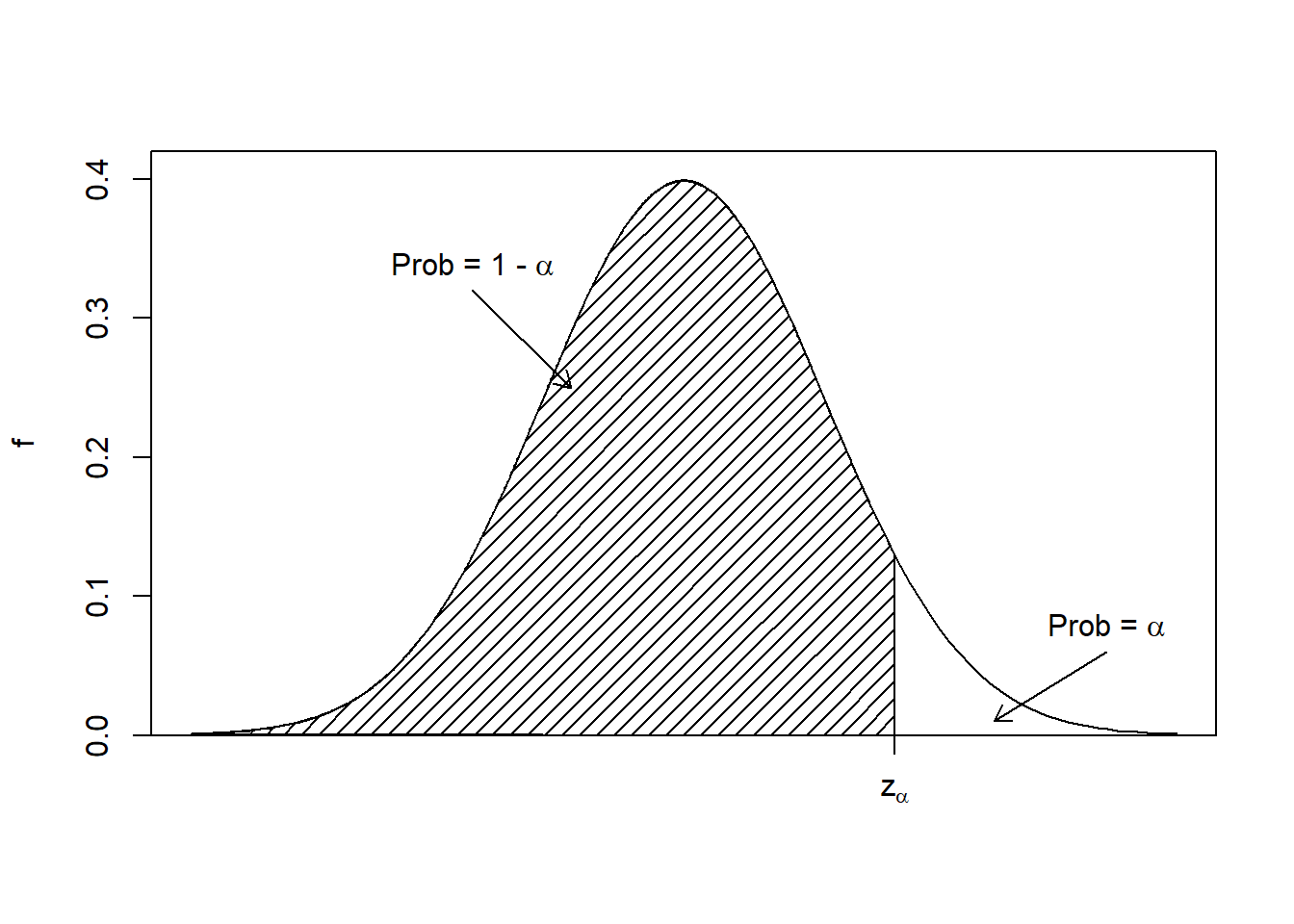
Figure 22.2: The pdf of a standard normal distribution, showing the idea of how to develop a one-sided confidence interval.
22.3 Confidence intervals for one proportion
In Chapters 18 and 19, we had an example of a single proportion. A Stanford University graduate student conducted an experiment using the tapper-listener game. The tapper picks a well-known song, taps the tune, and sees if the listener can guess the song. The researcher wanted to know whether a 50% correct-guess rate was a reasonable expectation. There was no second variable to shuffle, so we were unable to use a randomization test with this example. However, we used the CLT and simulation with a binomial probability model to perform hypothesis tests. In this section, we will use a confidence interval to answer our research question, and compare it to the results from hypothesis testing.
In the study, 42 out of 120 listeners (\(\hat{p} = 0.35\)) correctly guessed the tune.
22.3.1 Confidence interval for one proportion using the normal model
The conditions for applying the normal model were already verified in Chapter 19; the number of successes and failures is at least 10 and each guess (observation) is an independent observation from a binomial distribution. Thus, we can proceed to the construction of the confidence interval. Remember, the form of the confidence interval is
\[\text{point estimate} \ \pm\ z^{\star}\times SE\]
Our point estimate is \(\hat{p} = 0.35\). The standard error is slightly different because we don’t know the true (or hypothesized) value of \(\pi\). Instead, we can use \(\hat{p}\) to estimate \(\pi\).
\[SE = \sqrt{\hat{\pi} (1 - \hat{\pi}) \over n}\]
\[SE \approx \sqrt{0.35(1 - 0.35) \over 120} = 0.0435\]
The critical value, the number of standard deviations needed for the confidence interval, is found from the normal quantile.
qnorm(0.975)## [1] 1.959964Then, the 95% confidence interval is
\[0.35 \pm 1.96\times 0.0435 \qquad \rightarrow \qquad (0.265, 0.435)\]
We are 95% confident that the true correct-guess rate in the tapper-listener game is between 26.5% and 43.5%. Since this does not include 50% (or 0.50), we are confident the true correct-guess rate is different from 50%. This supports the results from the hypothesis tests, both of which resulted in \(p\)-values around 0.001, leading us to reject the null hypothesis and conclude that the true correct-guess rate was different from 50%.
Of course, R has built-in functions to perform the hypothesis test and calculate the confidence interval for a single proportion.
prop_test(x = 42, n = 120, p = 0.5)##
## 1-sample proportions test with continuity correction
##
## data: 42 out of 120
## X-squared = 10.208, df = 1, p-value = 0.001398
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.2667083 0.4430441
## sample estimates:
## p
## 0.35
binom.test(x = 42, n = 120)##
##
##
## data: 42 out of 120
## number of successes = 42, number of trials = 120, p-value = 0.001299
## alternative hypothesis: true probability of success is not equal to 0.5
## 95 percent confidence interval:
## 0.2652023 0.4423947
## sample estimates:
## probability of success
## 0.35Both functions give similar confidence intervals. The documentation for prop_test() and binom.test() provide details on additional options, such as one-sided intervals and different confidence levels.
The \(p\)-values are a little different than the ones we calculated (0.0012 for the simulation and 0.0010 for the normal-based test) because a correction factor was applied in prop_test() and a different type of interval was used in binom.test(). We leave it to the reader to learn more about these functions and related topics online. The code below calculates the confidence interval without a continuity correction. This confidence interval is closer to what we calculated by hand, and we come to the same conclusion because 50% is not contained in the interval.
prop_test(x = 42, n = 120, p = 0.5, correct = FALSE)##
## 1-sample proportions test without continuity correction
##
## data: 42 out of 120
## X-squared = 10.8, df = 1, p-value = 0.001015
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.2705190 0.4387868
## sample estimates:
## p
## 0.3522.4 Confidence intervals for two proportions
Throughout hypothesis testing, we had several examples of two proportions. We tested these problems with a randomization test or using a hypergeometric distribution. But in our chapters and homework, we have not presented the hypothesis test for two proportions using the asymptotic normal distribution, the central limit theorem. In this section, we will use a confidence interval to answer our research question, and compare it to the results from hypothesis testing.
In Chapters 17 and 18, we encountered an experiment that investigated whether providing blood thinners to patients who received CPR for a heart attack helped or hurt survival. It is believed that blood thinners (treatment group) negatively affect internal injuries that may result from CPR, leading to lower survival rates. The results from the experiment, which included 90 patients, are summarized in the R code below. These results are surprising! The point estimate suggests that patients who received blood thinners may have a higher survival rate: \[p_{\text{treatment}} - p_{\text{control}} = 0.13\].
thinner <- read_csv("data/blood_thinner.csv")
tally(~ group + outcome, data = thinner, margins = TRUE)## outcome
## group died survived Total
## control 39 11 50
## treatment 26 14 40
## Total 65 25 90
tally(outcome ~ group, data = thinner, margins = TRUE, format = "proportion")## group
## outcome control treatment
## died 0.78 0.65
## survived 0.22 0.35
## Total 1.00 1.00
obs <- diffprop(outcome ~ group, data = thinner)
obs## diffprop
## -0.13Notice that because R uses the variable names in alphabetic order, we have \(p_{\text{control}} - p_{\text{treatment}} = -0.13\). This is not a problem. We could fix this by changing the variables to factors and reordering the levels.
22.4.1 Confidence interval for two proportions using the normal model
The conditions for applying the normal-based model (i.e., CLT) are met: the number of successes and failures in each group is at least 10 and each observation can be thought of as an independent observation from a hypergeometric distribution. Thus, we can proceed to the construction of the confidence interval. The form of the confidence interval is
\[\text{point estimate} \ \pm\ z^{\star}\times SE\]
Our point estimate is -0.13. The standard error is different here because we can’t assume the proportion of survival is equal for both groups. We will estimate the standard error with
\[SE = \sqrt{\frac{p_{\text{control}}(1 - p_{\text{control}})}{n_{\text{control}}} + \frac{p_{\text{treatment}}(1 - p_{\text{treatment}})}{n_{\text{treatment}}}}\]
where \(p_{\text{control}}\) and \(p_{\text{treatment}}\) are the proportion of patients who survive in the control group and treatment group, respectively. Thus, we have
\[SE \approx \sqrt{\frac{0.22(1 - 0.22)}{50} + \frac{0.35(1 - 0.35)}{40}} = 0.0955\]
It is close to the pooled value102 because of the nearly equal sample sizes.
The critical value is again found from the normal quantile.
qnorm(.975)## [1] 1.959964The 95% confidence interval is
\[ -0.13 \pm 1.96\times 0.0955 \qquad \rightarrow \qquad (-0.317, 0.057)\]
We are 95% confident that the difference in proportions of survival for the control and treatment groups is between -0.317 and 0.057. Because this does include zero, we are not confident they are different. This supports our conclusions from the hypothesis tests; we found a \(p\)-value of around 0.26 and failed to reject the null hypothesis that the two proportions were different, or that the difference in the two proportions was different from zero.
Note that this confidence interval is not an accurate method for smaller samples sizes. This is because the actual coverage rate, the percentage of intervals that contain the true population parameter, will not be the nominal, stated, coverage rate. This means it is not true that 95% of similarly constructed 95% confidence intervals will contain the true parameter. This is because the pooled estimate of the standard error is not accurate for small sample sizes. For the example above, the sample sizes are large enough and the performance of the method should be adequate.
The prop_test() function in R, used for the single proportion example, can also be used to calculate the hypothesis test and confidence interval for two proportions.
prop_test(outcome ~ group, data = thinner)##
## 2-sample test for equality of proportions with continuity correction
##
## data: tally(outcome ~ group)
## X-squared = 1.2801, df = 1, p-value = 0.2579
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.07966886 0.33966886
## sample estimates:
## prop 1 prop 2
## 0.78 0.65The \(p\)-value is close to the one found in the randomization test, which is an approximation of the exact permutation test, because a correction factor was applied. We again provide code below without the correction factor and get a \(p\)-value more similar to that found using the hypergeometric distribution, and a confidence interval more similar to what we calculated above. The confidence interval is a little different because the function used died as its success event, but since zero is contained in the interval, we get the same conclusion.
prop_test(outcome ~ group, data = thinner, correct = FALSE)##
## 2-sample test for equality of proportions without continuity
## correction
##
## data: tally(outcome ~ group)
## X-squared = 1.872, df = 1, p-value = 0.1712
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.05716886 0.31716886
## sample estimates:
## prop 1 prop 2
## 0.78 0.65Essentially, confidence intervals and hypothesis tests serve similar purposes, but answer slightly different questions. A confidence interval gives you a range of feasible values of a parameter, given a particular sample. A hypothesis test tells you whether a specific value is feasible, given a sample. Sometimes you can informally conduct a hypothesis test simply by building an interval and observing whether the hypothesized value is contained in the interval. The disadvantage to this approach is that it does not yield a specific \(p\)-value. The disadvantage of the hypothesis test is that it does not give a range of feasible values for the test statistic.
As with hypothesis tests, confidence intervals are imperfect. About 1-in-20 properly constructed 95% confidence intervals will fail to capture the parameter of interest. This is a similar idea to our Type 1 error.
22.5 Changing the confidence level
Suppose we want to consider confidence intervals where the confidence level is somewhat higher than 95%; perhaps we would like a confidence level of 99%. Think back to the analogy about trying to catch a fish: if we want to be more sure that we will catch the fish, we should use a wider net. To create a 99% confidence level, we must also widen our 95% interval. On the other hand, if we want a more narrow interval, we must calculate an interval with lower confidence, such as 90%.
The 95% confidence interval structure provides guidance in how to make intervals with new confidence levels. Below is a general 95% confidence interval for a point estimate that comes from a nearly normal distribution:
\[\text{point estimate}\ \pm\ 1.96\times SE \]
There are three components to this interval: the point estimate, “1.96”, and the standard error. The choice of \(1.96\times SE\), which is also called margin of error, was based on capturing 95% of the data because the estimate is within 1.96 standard errors of the true value about 95% of the time. The choice of 1.96 corresponds to a 95% confidence level. Thinking back to the 68-95-99.7 rule for the normal distribution (see the homework in Chapter 13) may be helpful here as well.
Exercise: If \(X\) is a normally distributed random variable, how often will \(X\) be within 2.58 standard deviations of the mean?103
To create a 99% confidence interval, change 1.96 in the 95% confidence interval formula to be \(2.58\). We can use qnorm() to calculate this value. Remember that qnorm() uses the lower tail probability, so if we want 0.99 probability in the middle of the interval, we need to use 0.995 in the function. Follow the same reasoning to calculate confidence intervals with different confidence levels.
qnorm(0.995)## [1] 2.575829The normal approximation is crucial to the precision of these confidence intervals. In the next chapter, we will learn a method called the bootstrap that will allow us to find confidence intervals without the assumption of normality.
22.6 Changing the sample size
Exercise: By how much do we have to increase the sample size in order to reduce the margin of error by half?104
The equation for a confidence interval for a mean is
\[ \bar{x} \pm t_{\alpha/2, n - 1}{s \over \sqrt{n}} \]
and the equation for a confidence interval for a proportion is
\[ \hat{p} \pm z_{\alpha/2}\sqrt{\hat{\pi} (1 - \hat{\pi}) \over n} \]
The margin of error is the critical value multiplied by the standard error, the right side of each expression. In both equations, we have \(\sqrt{n}\) in the denominator of the standard error. Suppose we calculate a confidence interval based on a sample size of 100. Then, a confidence interval based on a sample size of 200 would have a standard error that is reduced by a factor of \(1/\sqrt{2}\). Compared to the original interval (sample size of 100), a confidence interval based on a sample size of 400 would have a standard error that is reduced by a factor of \(1/\sqrt{4} = 1/2\). As the sample size increases, the standard error (and hence, the margin of error) decreases, and the interval gets more narrow. We can think of this another way: as the sample size increases and we gain more information about the population, our confidence interval gets more precise. A smaller sample size (less information about the population) results in a wider confidence interval.
22.7 Interpreting confidence intervals
A careful eye might have observed the somewhat awkward language used to describe confidence intervals.
Correct interpretation:
We are XX% confident that the population parameter is between lower bound and upper bound.
Correct interpretation:
Approximately 95% of similarly constructed intervals will contain the population parameter.
Incorrect language might try to describe the confidence interval as capturing the population parameter with a certain probability. This is one of the most common errors. While it might be useful to think of it as a probability, the confidence level only quantifies how plausible it is that the parameter is in the interval. Once again, we remind the reader that we do not make probabilistic statements about a realized interval; there are no random components in the interval once we observe data, so there is no probability associated with the calculated interval.
Another especially important consideration of confidence intervals is that they only try to capture the population parameter. Our intervals say nothing about the confidence of capturing individual observations, a proportion of the observations, or point estimates. Confidence intervals only attempt to capture population parameters.
22.8 Homework Problems
- Chronic illness
In 2013, the Pew Research Foundation reported that “45% of U.S. adults report that they live with one or more chronic conditions”.105 However, this value was based on a sample, so it may not be a perfect estimate for the population parameter of interest on its own. The study reported a standard error of about 1.2%, and a normal model may reasonably be used in this setting.
Create a 95% confidence interval for the proportion of U.S. adults who live with one or more chronic conditions. Also interpret the confidence interval in the context of the study.
Create a 99% confidence interval for the proportion of U.S. adults who live with one or more chronic conditions. Also interpret the confidence interval in the context of the study.
Identify each of the following statements as true or false. Provide an explanation to justify each of your answers.
- We can say with certainty that the confidence interval from part a) contains the true percentage of U.S. adults who suffer from a chronic illness.
- If we repeated this study 1,000 times and constructed a 95% confidence interval for each study, then approximately 950 of those confidence intervals would contain the true fraction of U.S. adults who suffer from chronic illnesses.
- The poll provides statistically significant evidence (at the \(\alpha = 0.05\) level) that the percentage of U.S. adults who suffer from chronic illnesses is not 50%.
- A standard error of 1.2% means that only 1.2% of people in the study communicated uncertainty about their answer.
- Suppose the researchers had formed a one-sided hypothesis, they believed that the true proportion is less than 50%. We could find an equivalent one-sided 95% confidence interval by taking the upper bound of our two-sided 95% confidence interval.
- Vegetarian college students
Suppose that 8% of college students are vegetarians. Determine if the following statements are true or false, and explain your reasoning.
The distribution of the sample proportions of vegetarian college students in random samples of size 60 is approximately normal since \(n \ge 30\).
The distribution of the sample proportions of vegetarian college students in random samples of size 50 is right skewed.
A random sample of 125 college, students where 12% are vegetarians, would be considered unusual.
A random sample of 250 college, students where 12% are vegetarians, would be considered unusual.
The standard error would be reduced by one-half if we increased the sample size from 125 to ~250.
A 99% confidence interval will be wider than a 95% because having a higher confidence level requires a wider interval.
- Orange tabbies
Suppose that 90% of orange tabby cats are male. Determine if the following statements are true or false, and explain your reasoning.
The distribution of the sample proportions of male orange tabby cats in random samples of size 30 is left skewed.
Using a sample size that is 4 times as large will reduce the standard error of the sample proportion by one-half.
The distribution of the sample proportions of male orange tabby cats in random samples of size 140 is approximately normal.
- Working backwards
A 90% confidence interval for a population mean is (65, 77). The population distribution is approximately normal and the population standard deviation is unknown. This confidence interval is based on a simple random sample of 25 observations. Calculate the sample mean, the margin of error, and the sample standard deviation.
- Sleep habits of New Yorkers
New York is known as “the city that never sleeps”. A random sample of 25 New Yorkers were asked how much sleep they get per night. Statistical summaries of these data are shown below. Do these data provide strong evidence that New Yorkers sleep less than 8 hours per night on average?
\[ \begin{array}{ccccc} & & &\\ \hline n & \bar{x} & s & min & max \\ \hline 25 & 7.73 & 0.77 & 6.17 & 9.78 \\ \hline \end{array} \]
Write the hypotheses in symbols and in words.
Check conditions, then calculate the test statistic, \(T\), and the associated degrees of freedom.
Find and interpret the \(p\)-value in this context.
What is the conclusion of the hypothesis test?
Construct a 95% confidence interval that corresponded to this hypothesis test, would you expect 8 hours to be in the interval?
- Vegetarian college students II
From Problem 2 part c), suppose that it has been reported that 8% of college students are vegetarians. We think USAFA is not typical because of their fitness and health awareness, we think there are more vegetarians. We collect a random sample of 125 cadets and find 12% claimed they are vegetarians. Is there enough evidence to claim that USAFA cadets are different?
Use
binom.test()to conduct the hypothesis test and find a confidence interval.Use
prop.test()withcorrect = FALSEto conduct the hypothesis test and find a confidence interval.Use
prop.test()withcorrect = TRUEto conduct the hypothesis test and find a confidence interval.Which test should you use?